
개체의 변동과 집단의 변동은 서로 연관되면서도 각기 다른 현상을 나타냅니다. 개체의 변동은 하나의 집단 내 개체 간 차이로, 유전, 환경 등에 의해 발생하며 집단 내 다양성을 나타냅니다. 반면, 집단의 변동은 서로 다른 집단들 간 차이로, 연령, 성별 등 변수에 기반해 발생하며 집단 간 차이의 정도를 나타냅니다. 이 두 변동은 상호작용하며, 집단 간 큰 차이는 구분 변수의 영향을, 집단 내 큰 변동은 개체의 유전적, 환경적 다양성의 영향을 나타냅니다. 변동은 평균에서의 편차제곱의 합이며, 확률변수로, 집단의 크기가 커지면 변동도 커지빈다. 각 부분집단의 변동은 집단 크기에 따라 다르며, 전체집단의 변동은 부분집단의 변동의 합과 같습니다. 변동을 이해하는 것은 집단 내외 요인의 상호작용 이해에 중요하며, 분산분석에서는 이러한 변동을 세 가지 제곱합으로 나누어 분석합니다. 처리제곱합(집단 간 변동), 오차제곱합(집단 내 변동), 총제곱합(전체 변동)입니다.
개체의 변동(individual variation)과 집단의 변동(group variation)은 서로 연관되어 있으면서도 각기 다른 현상을 나타냅니다.
개체의 변동은 하나의 집단 내에서 각 개체 간의 차이를 나타냅니다. 이 변동은 유전, 환경, 생활 방식 등 다양한 요인에 의해 발생할 수 있습니다. 예를 들어, 한 반의 학생들 사이에서 시험 점수의 차이, 키의 차이 등은 개체 간 변동의 예시입니다. 개체의 변동은 집단 내 다양성의 정도를 나타냅니다.
집단의 변동은 서로 다른 집단들 간의 차이를 나타냅니다. 이는 집단을 구분하는 특정 변수(예: 연령, 성별, 지역 등)에 기반한 변동을 의미합니다. 예를 들어, 다양한 연령대의 사람들 사이에서 운동 능력의 차이, 여러 지역에서 수확되는 작물의 수량 차이 등은 집단 간 변동의 예시입니다. 집단의 변동은 집단 간 차이의 정도를 나타내며, 이러한 차이는 특정 변수의 영향을 이해하거나 집단 간 비교를 하는 데 중요한 기준이 됩니다.
개체의 변동과 집단의 변동은 서로 상호작용합니다. 예를 들어, 집단 간에 큰 차이가 관찰될 경우, 이는 해당 집단을 구분하는 명목형 변수(예: 지역, 성별 등)가 개체의 특성에 큰 영향을 미치고 있다는 것을 추론할 수 있습니다. 반대로, 집단 간 변동이 작지만 집단 내 변동이 큰 경우, 이는 개체의 유전적, 환경적 다양성이 해당 현상에 큰 영향을 미치고 있음을 나타낼 수 있습니다. 따라서, 이 두 변동을 함께 분석하는 것은 집단 내외의 다양한 요인이 어떻게 상호작용하여 특정 패턴이나 현상을 생성하는지 이해하는 데 중요합니다.
변동(variation)은 평균에서의 편차의 제곱의 합이며 확률변수입니다. 변동은 편차제곱의 합으로 표현되므로 양수이고 집단의 크기도 영향을 미칩니다. 예를 들어, 표본의 크기가 커지면 표본의 변동도 커집니다.
확률변수, $Y$를 종속변수(반응변수)로 하고 명목형 변수 $X$를 독립변수(설명변수)로 할 때 종속변수의 편차제곱$(Y-\mu_Y)^2$은 확률변수입니다. 확률변수 $Y$가 실현된 집단이 한 명목형 변수($X$)에 따라 독립된 부분집단(Group)으로 나누어지고 $i$번째 부분집단의 확률변수를 $Y_i$라 할 때 확률변수($Y_i$)의 편차제곱인 $(Y_i-\mu_{Y_i})^2$도 확률변수가 됩니다.
$i$번째 부분집단의 표본분산인 $S_{Y_i}^2$은 표본평균인 $\bar {Y_i}$를 기준으로 하는 편차제곱의 평균이며 확률변수입니다. 각 부분집단의 표본의 분산을 확률변수 $S_{Y_1}^2$, $S_{Y_2}^2$ , … , $S_{Y_i}^2$로 나타내고 각 부분집단의 모분산은 $\sigma_{Y_1}^2$, $\sigma_{Y_2}^2$ , … , $\sigma_{Y_i}^2$로 나타냅니다.
만일, 여러 부분집단의 평균이 같다고 가정하면, 다음식을 성립하며 $\chi^2$ 확률분포를 나타냅니다.
$$(n_1 + n_2 + , … , + n_i – i) \dfrac {S_Y^2}{\sigma_Y^2} =(n_1-1)\dfrac{S_{Y_1}^2}{\sigma_{Y_1}^2}+(n_2-1)\dfrac{S_{Y_2}^2}{\sigma_{Y_2}^2}+, … , (n_i-1)\dfrac{S_{Y_i}^2}{\sigma_{Y_i}^2}\sim\chi^2$$
여기서, $n_1, n_2, … , n_i$는 각 부분집단의 표본크기
$i$는 부분집단수
$\chi^2$의 자유도는 $n_1 + n_2 +, … , n_i – i$
$S_Y^2$는 전체집단의 표본분산
$\sigma_Y^2$는 전체집단의 모분산
$S_{Y_1}^2$, $S_{Y_2}^2$ , … , $S_{Y_i}^2$는 각 부분집단의 표본분산
$\sigma_{Y_1}^2, \sigma_{Y_2}^2, … , , \sigma_{Y_i}^2$는 각 부분집단의 모분산
표본분산의 통합분산을 도입하면 다음식과 같습니다.
$$(n_1-1)\dfrac{S_{Y_1}^2}{\sigma_{Y_1}^2}+(n_2-1)\dfrac{S_{Y_2}^2}{\sigma_{Y_2}^2}+, … , (n_i-1)\dfrac{S_{Y_i}^2}{\sigma_{Y_i}^2} \approx (n_1 + n_2 + , … , + n_i – i) \dfrac {S_p^2}{\sigma_Y^2} $$
각 부분집단의 변동은 집단크기에 따라 다르지만 모분산은 같다고 모델링할 수 있고 다음식으로 표현합니다.
$$\sigma_{Y}^2 = \sigma_{Y_1}^2 = \sigma_{Y_i}^2$$
따라서, 전체집단을 이루는 각 부분집단이 독립일 경우, 전체집단의 $\chi^2$은 각 부분집단의 $\chi^2$의 합과 같습니다. 전체집단의 표본통합분산($S_p^2$)은 각 부분집단의 표본분산의 가중평균으로 볼 수 있습니다. 여기서 가중은 자유도의 비로 주어집니다.
$$({n_1}+{n_2}+, … , +{n_i}-i){S_p^2}∼({n_1}-1)S_{Y_1}^2+({n_2}-1)S_{Y_2}^2, … , ({n_i}-1)S_{Y_i}^2$$
$$S_p^2=\dfrac{n_1-1}{n_1+n_2+, … , +n_i-i}{S_{Y_1}^2}+\dfrac{n_2-1}{n_1+n_2+, … , +n_i-i}{S_{Y_2}^2}+, … , +\dfrac{n_i-1}{n_1+n_2+, … , +n_i-i}{S_{Y_i}^2}$$
여기서, $n_1, n_2, … , n_i$는 각 부분집단의 표본크기
$S_p^2$는 전제집단의 표본분산의 통합분산(pooled variance)
$S_{Y_1}^2, S_{Y_2}^2, … , S_{Y_i}^2$는 각 부분집단의 표본분산
전체집단의 모평균을 기준으로 구한 부분집단의 변동은 확률변수 카이제곱($\chi^2$)으로 표현할 수 있습니다. 그리고 각 부분집단의 모평균을 기준으로 하는 변동도 확률변수이며 각각 $\chi_1^2$, $\chi_2^2$ , … , $\chi_i^2$로 표현합니다. 그리고 $X^2$대신에 그리스문자인 $\chi^2$을 사용하는 이유는 기준이 0이 아니고 집단의 모평균임을 나타내기 위함입니다.
$$(n_1 + n_2 + , … , + n_i – i) \dfrac {S_Y^2}{\sigma_Y^2}=(n_1-1)\dfrac{S_{Y_1}^2}{\sigma_{Y_1}^2}+(n_2-1)\dfrac{S_{Y_2}^2}{\sigma_{Y_2}^2}+, … , (n_i-1)\dfrac{S_{Y_i}^2}{\sigma_{Y_i}^2}$$
윗식에서 각 부분집단의 표준화 스케일러는 다음과 같습니다.
$$ \dfrac{\sigma_{Y_i}^2}{(n_i – 1)}$$
모집단에서 추출한 표본의 표본평균의 오차(Standard Error of Mean)의 추정량(Estimator)은 다음과 같습니다.
$$\sigma_{\bar X} = \sqrt{\rm {Var}[\bar X]} = \dfrac { \sigma}{\sqrt {n}}$$
모집단에서 크기가 $n$인 표본을 추출하는 모델에서 확률변수 카이제곱 $\chi_{n-1}^2$은 다음과 같습니다.
$$(n-1)\dfrac{S^2}{\sigma^2} ∼ \chi_{n-1}^2$$
여기서, $\chi_{n-1}^2$의 자유도는 $(n – 1)$
확률변수, ($Y$)가 실현된 집단의 모분산 ($\sigma_{Y}^2$)의 점추정량은 표본분산($S_{Y}^2$)의 기대값인 ${\rm E}[S_Y^2]$(${\rm Var}[Y]$)입니다. 표본분산은 확률변수이며 표본크기가 작으면 “0”에 치우치는 비대칭 분포를 가지나 표본크기가 커질수록 정규분포에 가까워집니다. 그리고 표본분산을 모집단의 분산으로 나누고 자유도인 $(n_i – 1)$를 곱하면 자유도를 모수로 하는 카이제곱 확률변수가 되며 $\chi_{n-1}^2$로 표기합니다. 이 확률변수는 자유도에 따른 카이제곱분포(chi-squared distribution)를 가집니다.
크기가 $n$인 표본의 $\chi_{n-1}^2$의 평균은 표본크기인 $n$이 되고 $\chi_{n-1}^2$의 분산은 2n이 됩니다.
표본분산은 모분산의 점추정량입니다. 즉, $\sigma_Y^2$와 ${\rm E}[S_Y^2]$이 같습니다. 단, $n_i$가 클 때이고 bias를 보정한 표본분산은 모분산과 다음식과 같은 관계를 가집니다. 그 이유는 크기가 $n$인 집단의 자유도는 $n$인 반면 표본은 자유도가 $(n – 1)$ 이기 떄문입니다. 마찬가지로, 전체집단의 부분집합이고 크기가 $n_i$인 집단의 자유도가 $n_i$인 반면 표본의 자유도는 $(n_i – 1)$ 입니다.
$$n\sigma_Y^2 = (n-1)S_{Y}^2$$
$$\dfrac{\sigma_Y^2}{S_Y^2}=\dfrac{n-1}{n}$$
새로운 확률변수$\chi_{n-1}^2$를 유도합니다.
$$\chi_{n-1}^2 = (n-1)\dfrac{S_Y^2}{\sigma_Y^2}$$
여기서, $\chi^2$은 새로운 확률변수
$n$은 표본크기
$(n-1)$은 자유도(degree of freedom)
$S_Y^2$ 확률변수인 표본분산
$\sigma_Y^2$는 모분산
| 확률변수 | 확률분포 | 발표자 | 연도 | 비고 |
|---|---|---|---|---|
| $X$ | 정규분포 | 피에르 시몽 라플라스 (Pierre-Simon Laplace, 프랑스) | 1774 | 정규분포에 대한 연구는 다양한 자연 현상에서 나타나는 연속 확률분포로서 시작됨 |
| $Z$ | 표준정규분포 | 카를 프리드리히 가우스 (Carl Friedrich Gauss, 독일) | 1810 | 표준정규분포는 평균이 0이고 표준편차가 1인 정규분포, 가우스는 정규분포와 표준정규분포를 수식으로 정립 |
| $\chi^2$ | 카이제곱분포 | 카를 피어슨 (Karl Pearson, 영국) | 1900 | 카이제곱분포는 표준정규분포를 따르는 확률변수들의 제곱의 합의 분포 |
| $t$ | t분포 | 윌리엄 시일리 고셋 (William Sealy Gosset, 필명: Student, 영국) | 1908 | t분포는 모분산을 모를 때 표본분산으로 대체하여 구한 표본평균의 분포, 작은 표본크기에 유용 |
| $F$ | ANOVA에 사용된 확률분포 | 로널드 A. 피셔 (Ronald A. Fisher, 영국(호주), 유전육종학) | 1925 | ANOVA(분산분석)는 여러 집단 간 평균 비교, 집단간분산과 집단내분산 비인 F분포 사용 |
| $F$ | F분포 | 조지 W. 스네데커 (George W. Snedecor, 미국, 통계학, 농학, 생물학, 유전학) | 1934 | 두 카이제곱분포의 비율을 새 확률변수로 하여 확률분포로 수식으로 정립, 그 확률변수를 피셔를 기려 $F$로 명명, 분자 카이제곱의 자유도가 1인 경우 $F_{1, n-1}=t_{n-1}^2$이고 F의 분모 카이제곱의 자유도와 t의 자유도는 같음 |
확률변수 $Y$를 가지는 집단에서 각각 $n$을 크기로 하는 표본을 추출하면 표본의 분산($S_{Y}^2$)도 확률변수가 됩니다. 표본크기가 $n$인 표본의 분산($S_{Y}^2$)을 모분산($\sigma_Y^2$)으로 나누고 표본내 개체의 자유도($n-1$)를 곱하면 확률변수인 카이제곱($\chi^2$)이 되고 확률밀도함수의 매개변수(parameter)는 자유도가 됩니다. 표본크기가 커질수록 카이제곱은 정규분포를 나타냅니다. 카이제곱의 평균은 자유도이고 분산은 평균의 2배가 됩니다. 정리하면, 표본분산을 집단의 모분산으로 나누고 자유도를 곱하면 확률변수 카이제곱($\chi^2$)이 됩니다. 이 확률변수의 기대값은 표본크기에서 1인 자유도이고 분산은 자유도의 2배입니다.
$${\rm E}[\chi_{n-1}^2] = (n-1)\dfrac{{\rm E}[S_Y^2]}{\dfrac {(n-1){\sigma_Y^2}}{n}}= n$$
여기서, $\sigma_Y^2$는 집단의 모분산
$S_Y^2$는 표본분산
$n$은 표본크기
$(n-1)$은 자유도
확률변수, $\chi^2$의 기대값은 ${\rm E}[\chi^2]$으로 분산은 ${\rm Var}[\chi_{n-1}^2]$로 표현되며, 표본분산의 기대값은 $\sigma_{\chi^2}^2$으로 표기합니다. 그리고 다음식이 성립합니다.
${\rm Var}[\chi_{n-1}^2] =2n$
여기서, $n$은 표본크기
$(n-1)$은 자유도
확률변수 $Y_1$, $Y_2$를 가지는 독립된 두 집단에서 각각 $n_1$, $n_2$를 크기로 하는 두 표본을 추출하면 각 표본의 분산($S_{Y_1}^2$, $S_{Y_2}^2$)은 중심극한정리에 의해 연속형 확률변수가 되며 표본크기가 커질수록 확률밀도함수가 정규분포를 나타냅니다. 두 표본분산 조합의 비로 새로운 확률변수 $F$를 생성하면 새로운 확률변수의 분산( $\sigma_F^2$)도 확률변수가 됩니다. 이 새로운 확률변수의 기대값은 두 집단의 분산의 비입니다. 분산비로 생성된 확률변수의 기대값은 다음식으로 표현합니다.
$${\rm {E}}{[F]} ={\rm {E}}\left(\dfrac{\dfrac{S_{Y_1}^2}{\sigma_{Y_1}^2}}{\dfrac{S_{Y_2}^2}{\sigma_{Y_2}^2}}\right)=\dfrac {d_2}{d2-2}$$
여기서, $d_2$는 분모에 위치한 집단의 자유도: $ d_2 \lt 2$
$\sigma_{Y_1}^2, \sigma_{Y_2}^2$는 두 집단의 모분산이며 등분산 가정
$S_{Y_1}^2, S_{Y_2}^2$는 두 집단의 표본분산
$n_1, n_2$은 두 표본크기
분산분석의 세 가지 제곱합의 설명을 위해 먼저 다음 통계량을 정의합니다.
${\bar{Y}}_{i·}$는 $Y$ 의 $i$번째 수준에서의 관측값들의 평균
${\bar{Y}}_{··}$는 $Y$ 의 전체 관측값들의 총평균
분산분석의 세 가지 제곱합을 다음과 같이 표현합니다.
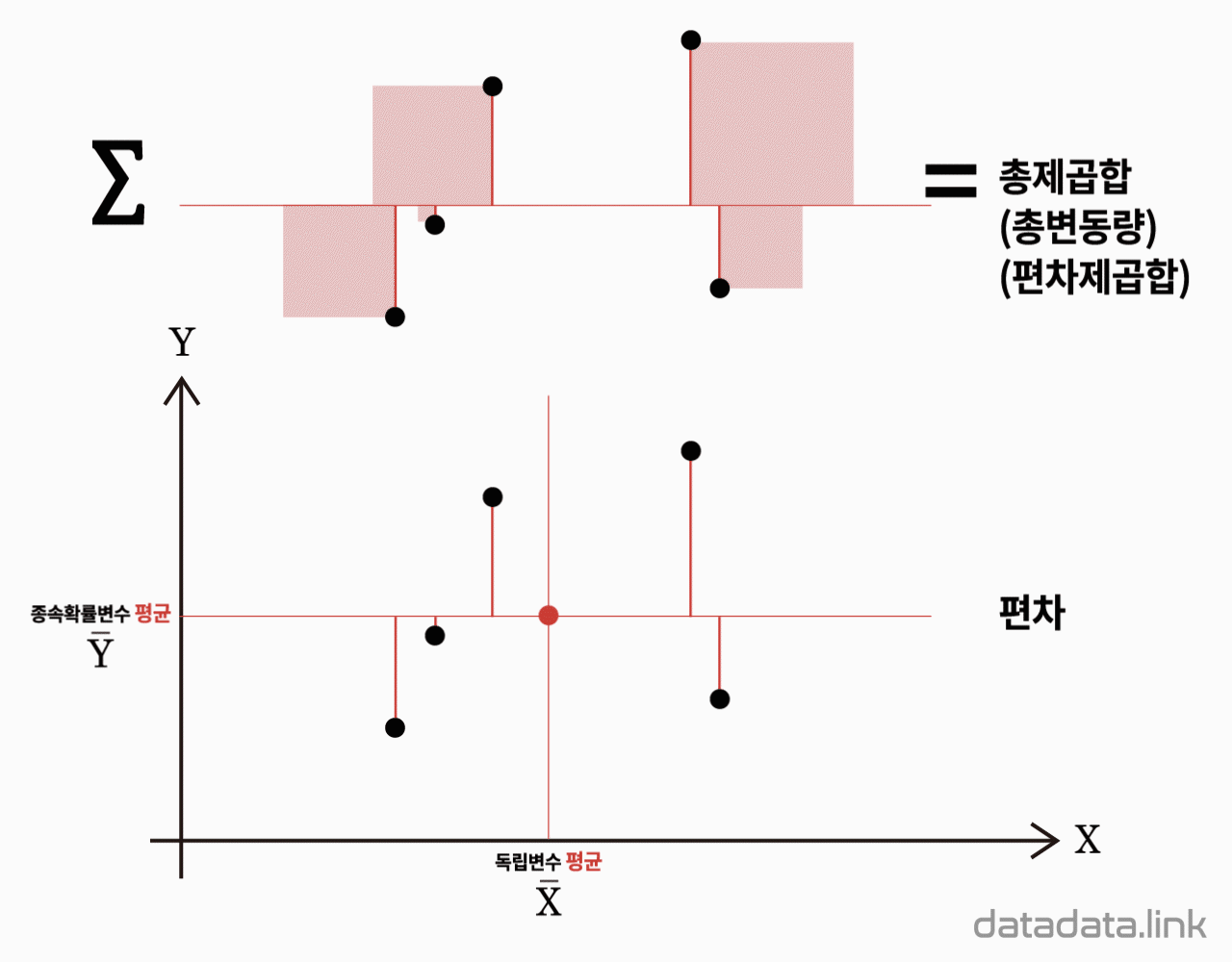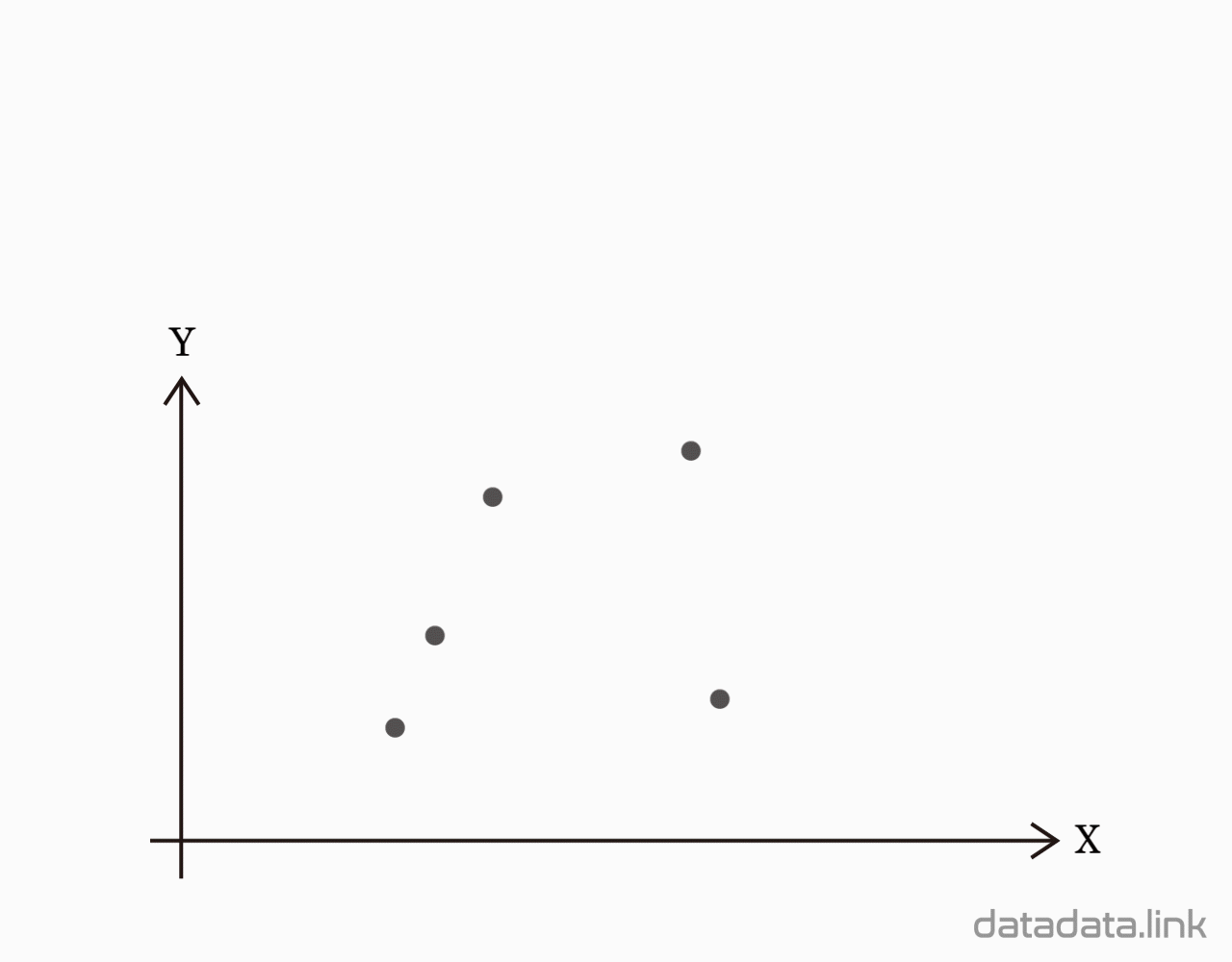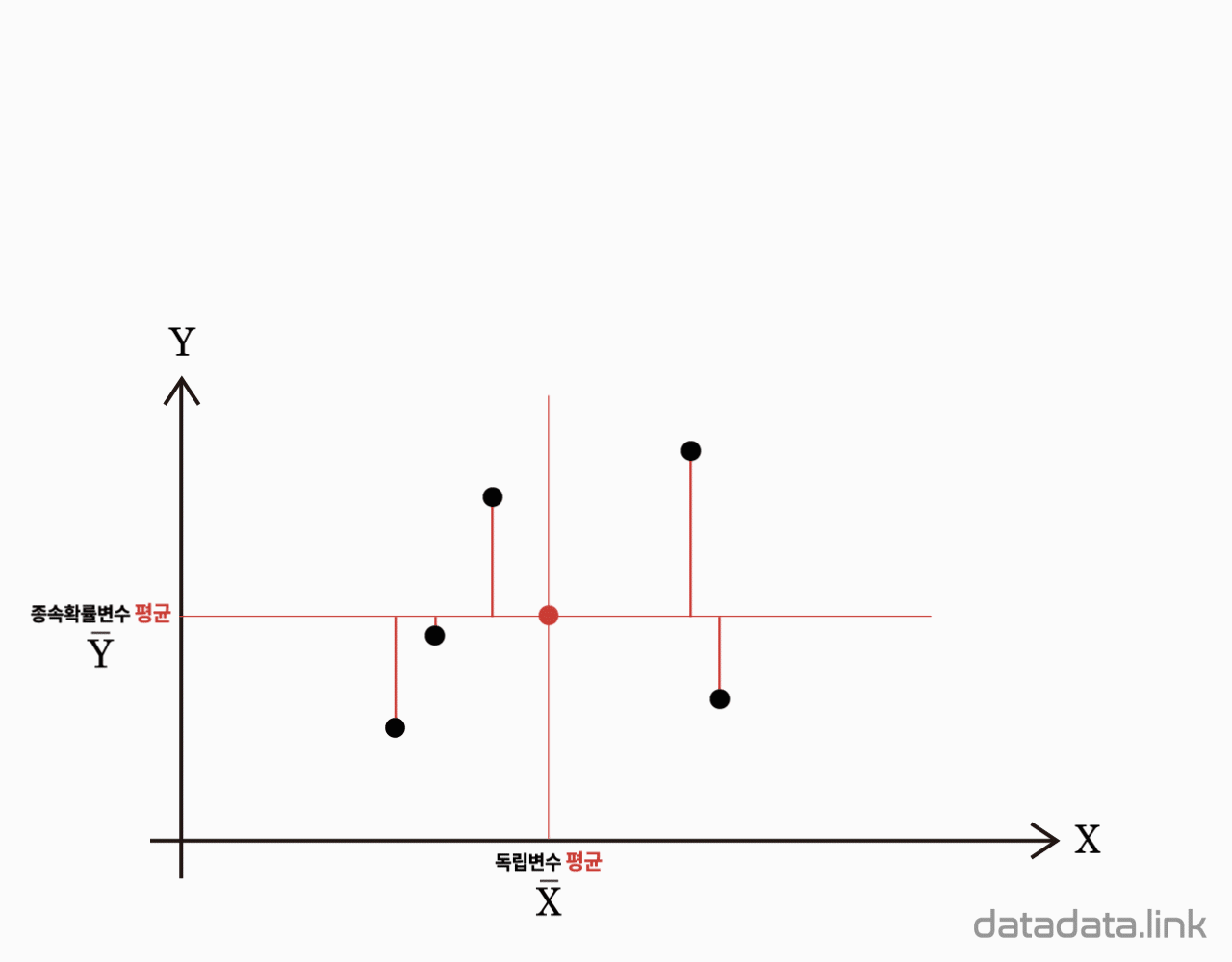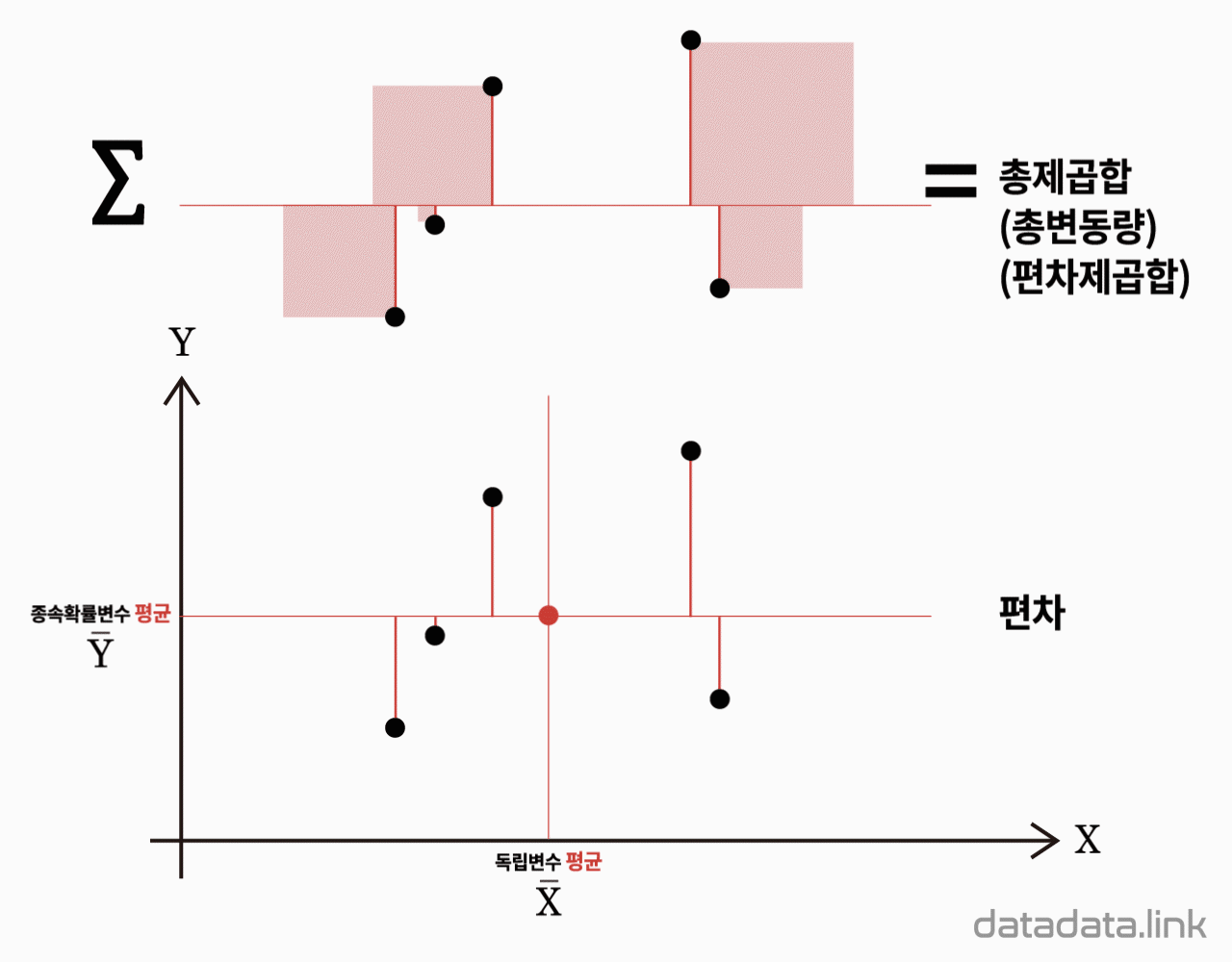
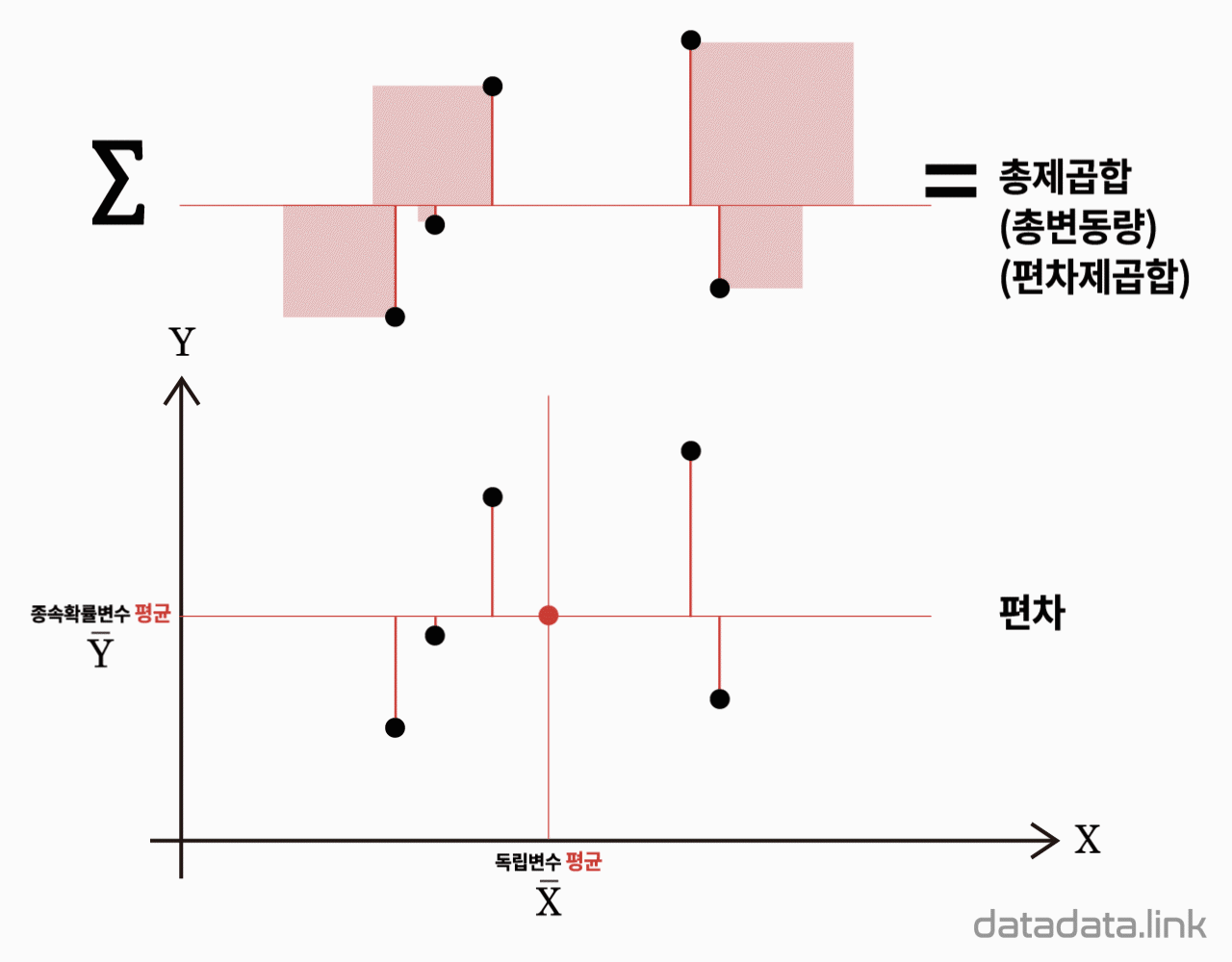
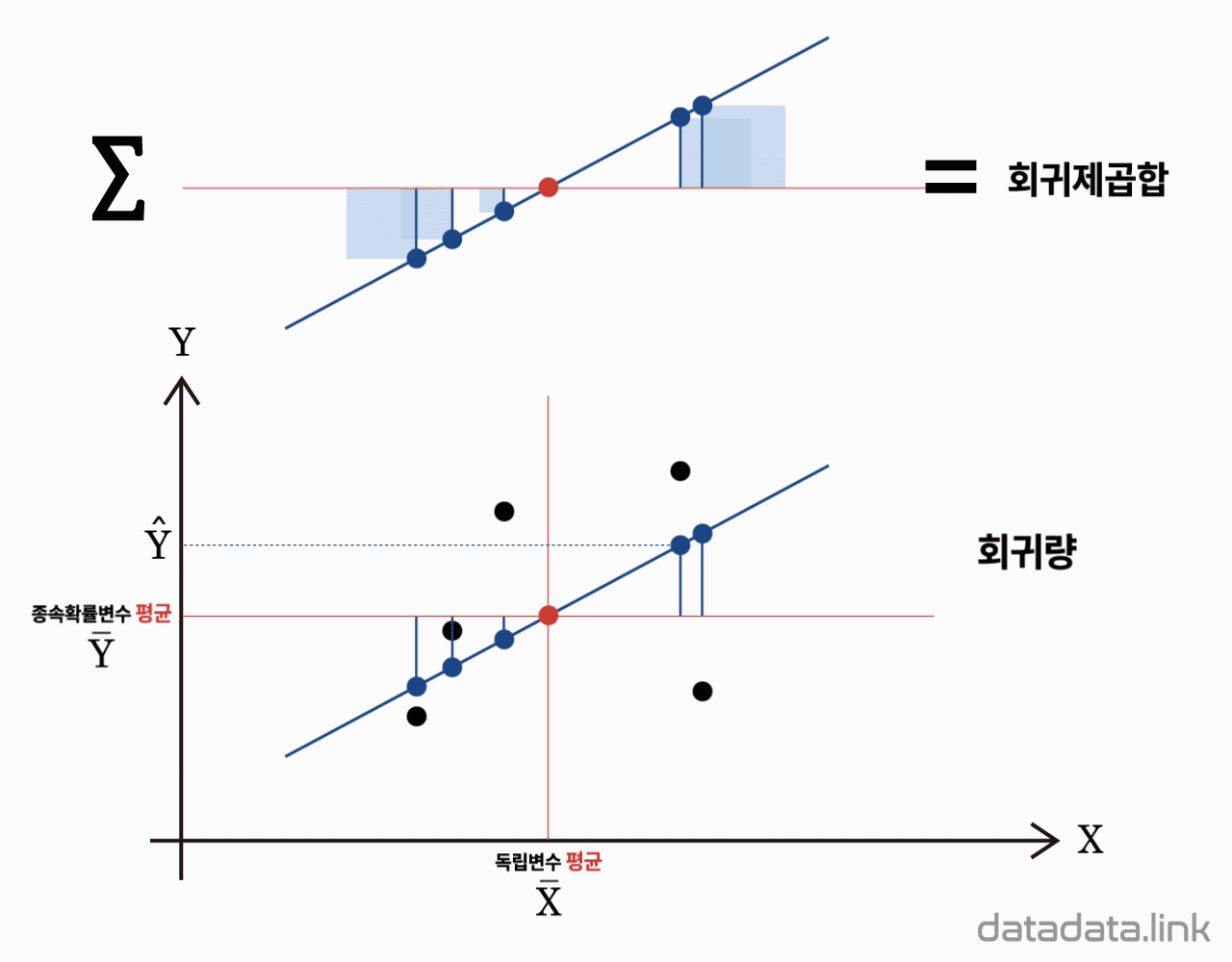
다음식과 같이 반응변수 $Y$의 관측값들과 총평균 사이의 거리의 제곱합을 총변동량 또는 총제곱합(total sum of squares, $\mathrm{SS_T}$)이라 합니다.
$${SS_T}{=}\mathop{\sum}\limits_{{i}{=}{1}}\limits^{k}{\mathop{\sum}\limits_{{j}{=}{1}}\limits^{{n}_{i}}{{(}{Y}_{ij}{-}{\bar{Y}}_{\cdot\cdot}{)}^{2}}}$$
다음식은 각 집단간의 차이에 의해 발생하는 변동량을 나타냅니다. $Y$의 $i$번째 집단에서의 관측값들의 평균 ${\bar{Y}}_{i·}$는 각 집단내의 변동량을 평균한 것으로 그 집단의 대표값이라 할 수 있습니다. 그러므로, 개개의 관측값 대신에 이 표본평균을 사용하여 총변동량을 구하면, 즉, 총제곱합을 구하는 공식에서 $Y_{ij}$ 대신에 ${\bar{Y}}_{i·}$를 대입하면 이는 집단간의 차이에 의한 변동량을 나타냅니다. 이와 같은 집단간의 변동량을 집단간변동량(between variation)이라 하며 이 변동량을 나타내는 제곱합을 처리제곱합(treatment sum of squares, $\mathrm{SSTr}$)이라 합니다.
$${SS_{Tr}}{=}\mathop{\sum}\limits_{{i}{=}{1}}\limits^{k}{\mathop{\sum}\limits_{{j}{=}{1}}\limits^{{n}_{i}}{{(}{\overline{Y}}_{{i}\cdot}{-}{\bar{Y}}_{\cdot\cdot}{)}^{2}}}$$
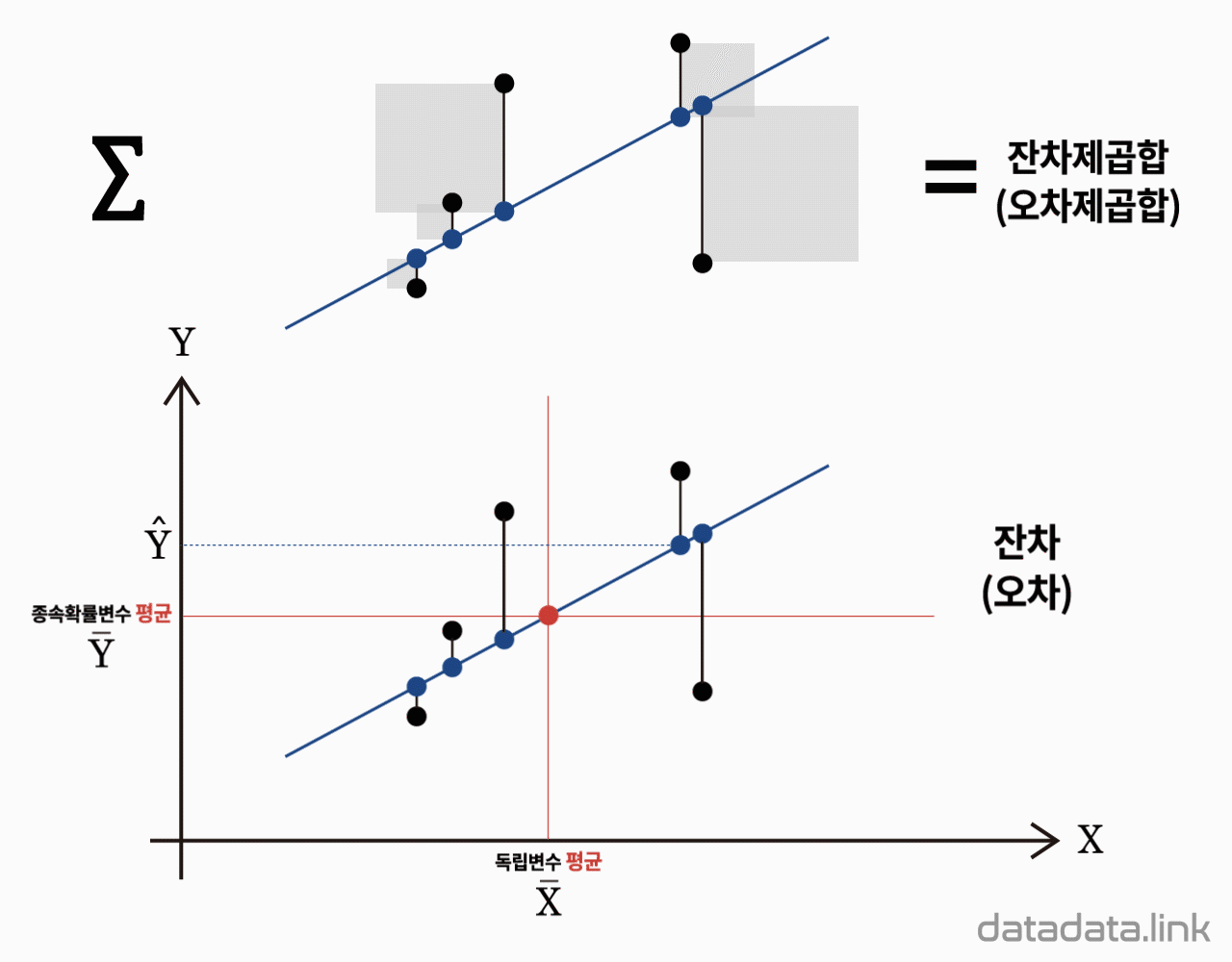
다음식은 각 집단내에서 발생하는 변동량들의 합을 나타냅니다. 각 집단내의 변동량을 집단내변동량(within variation)이라 하며, 이 집단내변동량을 나타내는 제곱합을 오차제곱합(error sum of squares, $\mathrm{SSE}$)이라 합니다.
$${SS_E}{=}\mathop{\sum}\limits_{{i}{=}{1}}\limits^{k}{\mathop{\sum}\limits_{{j}{=}{1}}\limits^{{n}_{i}}{{(}{Y}_{ij}{-}{\bar{Y}}_{{i}\cdot}{)}^{2}}}$$
각 제곱합이 가지는 자유도는 다음과 같이 구합니다. $SS_T$를 계산하기 위해서는 $n$개의 $Y_{ij}$ 값이 있지만, 먼저 전체평균의 추정량인 ${\bar{Y}}_{..}$을 계산해야하므로 $SS_T$는 자유도 $(n-1)$을 가지며, 오차제곱합 $SS_E$의 계산을 위해서는 $k$개의 값 ${\bar{Y}}_{1\cdot{}},\cdots,{\bar{Y}}_{k\cdot{}}$이 먼저 계산되므로 $SS_E$는 $(n-k)$의 자유도, 처리제곱합$SS_{Tr}$은 $SS_T$의 자유도에서 $SS_E$의 자유도를 뺀 나머지 $(k-1)$의 자유도를 가집니다.
분산분석(ANOVA)에서 “변동”은 데이터가 평균으로부터 얼마나 떨어져 있는지를 나타내는 측도입니다. 이는 데이터의 분산 정도를 나타내며, ANOVA에서 변동은 여러 구성 요소로 나뉩니다. ANOVA는 총변동을 집단간 변동과 집단내 변동으로 나눕니다.
총변동(Total Variation) – 총 제곱합 ($SS_T$, Total Sum of Squares): 전체 데이터의 변동을 나타냅니다. 이는 전체 데이터 포인트가 전체 평균으로부터 얼마나 떨어져 있는지를 측정합니다.
집단간 변동(Between-group Variation) – 집단간 제곱합 ($SS_B$, Sum of Squares Between): 각 집단의 평균들이 전체 평균으로부터 얼마나 떨어져 있는지를 나타냅니다. 이는 집단 간 차이에 기인한 변동입니다.
집단내 변동(Within-group Variation) – 집단내 제곱합 ($SS_W$, Sum of Squares Within): 같은 집단 내에서 개체가 그 집단의 평균으로부터 얼마나 떨어져 있는지를 나타냅니다. 이는 집단 내의 개체의 차이에 기인한 변동입니다.
종속변수의 평균이 편차제곱합의 기준입니다.
| 요인 Factor | 편차제곱합 Sum of Square | 자유도 | 편차제곱합의 평균 Mean Squared | F검정통계량 F value |
|---|---|---|---|---|
| 처리 Treatment | $SS_{Tr}$ | $k-1$ | $MS_{Tr}=\dfrac{SS_{Tr}}{k-1}$ | $F_0=\dfrac{MS_{Tr}}{MS_{E}}$ |
| 오차 Error | $SS_{E}$ | $n-k$ | $MS_{E}=\dfrac{SS_{E}}{n-k}$ | |
| 전체 Total | $SS_{T}$ | $n-1$ | 여기서, $n=\sum\limits_{i=1}\limits^{k}n_{i}$ |
종속변수의 평균이 기준입니다.
| 요인 Factor | 편차제곱합 Sum of Square | 자유도 | 편차제곱합의 평균 Mean Squared | F검정통계량 F value |
|---|---|---|---|---|
| 회귀 Regression | $SS_{Reg}$ | $2-1$ | $MS_{Reg}=\dfrac{SS_{Reg}}{2-1}$ | $F_0=\dfrac{MS_{Reg}}{MS_{Res}}$ |
| 잔차 Residual | $SS_{Res}$ | $n-2$ | $MS_{Res}=\dfrac{SS_{Res}}{n-2}$ | |
| 전체 Total | $SS_T$ | $n-1$ |
회귀선이 기준입니다.
| 요인 Factor | 편차제곱합 Sum of Square | 자유도 | 편차제곱합의 평균 Mean Squared | F검정통계량 F value |
|---|---|---|---|---|
| 잔차 Residual | $SS_{Res}$ | $n-2$ | $MS_{Res}=\dfrac{SS_{Res}}{n-2}$ | $F_0=\dfrac{MS_{Res}}{MS_E}$ |
| 오차 Error | $SS_E$ | $n-2$ | $MS_E=\dfrac{SS_E}{n-2}$ | |
| 전체 Total | $SS_T$ | $n-1$ |
종속변수의 평균과 독립변수의 평균이 만나는 점이 기준입니다.
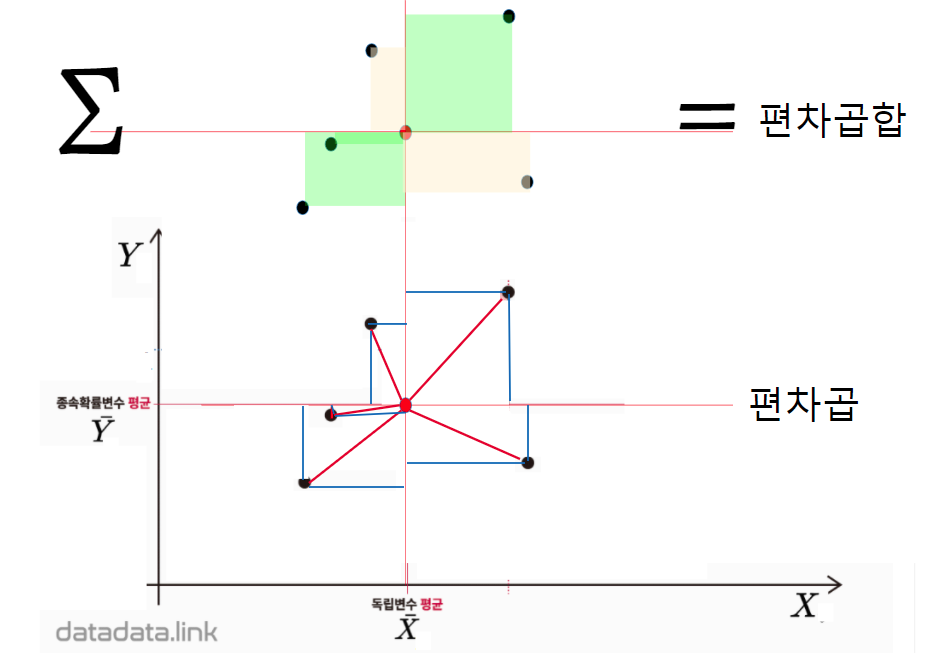
| 변동 Variation | 편차곱합 Sum of Products | 자유도 | 편차곱합의 평균 Mean Producted | F검정통계량 F value |
|---|---|---|---|---|
| X, Y 공분산 Cov[X, Y] | $SP_{Dev}$ $SP_{X, Y}$ | $n-1$ | $MP_{Dev}=\dfrac{SP_{Dev}}{n}=S_{XY}$=Cov[X, Y] | $F_0=\dfrac{MP_{Dev}}{MS_E}$ |
| $X$분산 Var{X] | $SS_{X}$ | $n-1$ | $MS_{X}=\dfrac{SS_X}{n-1}=S_X^2$=Var[X] | |
| $Y$분산 Var[Y} | $SS_{Y}$ | $n-1$ | $MS_X=\dfrac{SS_Y}{n-1}=S_Y^2$=Var[Y] |
종속변수의 평균과 독립변수의 평균이 만나는 점이 기준입니다.
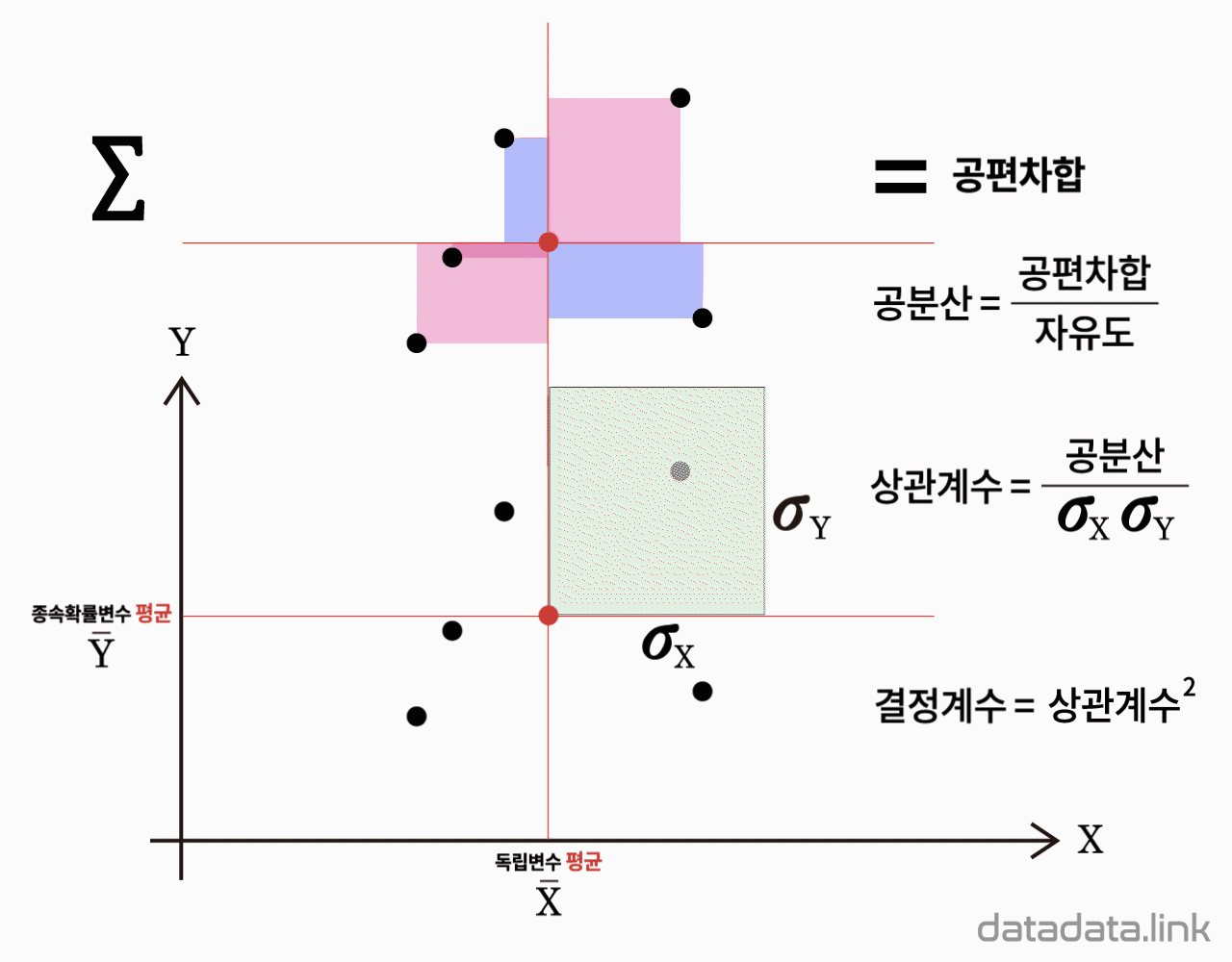
| 변동 Variation | 편차곱합 편차제곱합 Sum of Products Sum of Square | 자유도 | 관계 모수 relation parameter | F검정통계량 F value |
|---|---|---|---|---|
| X, Y 표본상관계수 $r_{X, Y}$ | $SP_{X, Y}$ $SS_{X}$ $SS_{Y}$ | $n-1$ $n-1$ $n-1$ | $r_{X, Y}=\dfrac{SP_{X,Y}}{\sqrt{SS_X}\sqrt{SS_Y}}=\dfrac{MS_X}{MS_Y}$ | $F_0=\dfrac{r^2}{1-r^2}$ |
| $X$분산 Var{X] | $SS_{X}$ | $n-1$ | $MS_X=\dfrac{SS_X}{n-1}=S_X^2$=Var[X] | 여기서, 결정계수: $R^2=r^2$ |
| $Y$분산 Var[Y} | $SS_{Y}$ | $n-1$ | $MS_Y=\dfrac{SS_Y}{n-1}=S_Y^2$=Var[Y] |
분산분석(ANOVA)은 집단평균의 차이를 분석하는 데 사용되는 일련의 통계모델(예: 집단 간 및 집단 내 “변동”)과 추정절차입니다. ANOVA는 통계학자 로널드 피셔(Ronald Fisher)에 의해 개발되었습니다. ANOVA는 분산합 법칙을 기반으로 하며, 특정 변수에서 관찰된 분산을 서로 다른 변동 원인에 기인한 구성 요소로 분할합니다. 가장 단순한 형태에서 ANOVA는 두 개 이상의 모집단 평균이 같은지 여부를 검정하는 통계적 검정을 제공합니다. 즉, ANOVA는 두 개 이상의 집단의 평균의 차이를 검정하는 데 사용됩니다.
출처
확률 이론과 통계학에서 변동계수(CV, Coefficient of Variation)는 정규화된 제곱근 평균 편차(NRMSD, normalized root-mean-square deviation), 백분율 RMS(percent RMS), 상대 표준 편차(RSD, relative standard deviation)라고도 불리며, 확률분포나 빈도분포의 분산을 표준화한 측도입니다. 이는 표준 편차(σ)를 평균(μ) 또는 그 절대값(|μ|)으로 나눈 비율로 정의되며, 종종 백분율(“%RSD”)로 표현됩니다. 변동계수(CV) 또는 상대 표준 편차(RSD)는 분석 화학에서 분석의 정확도와 재현성을 나타내는 데 널리 사용됩니다. 또한 품질 보증 연구, 측정 시스템의 신뢰성과 반복성을 평가, 공학이나 물리학 분야, 경제학자와 투자자들의 경제모델, 심리학/신경과학 분야 등에서 흔히 사용됩니다.
출처
금융에서 변동성(volality, σ)은 시간에 따른 연속된 거래 가격의 변동 정도를 의미하며, 일반적으로 로그 수익률의 표준 편차로 측정됩니다.
과거 변동성은 과거 시장 가격의 시계열을 측정합니다. 내재 변동성은 시간의 흐름에 따른 예측으로, 시장에서 거래되는 파생상품(특히 옵션)의 시장 가격에서 도출됩니다.
출처
1. 개체의 변동이 나타내는 것은 무엇인가요? 2 하
2. 집단 간 변동이 큰 경우, 이는 무엇을 나타낼 수 있나요? 1 상
3. 변동을 설명한 것은? 1 상
4. 표본분산을 모분산으로 나누고 자유도를 곱한 확률변수는 어떤 분포를 나타내나요? 2 중
5. 표본분산은 표본크기가 클수록 어떤 분포에 가까워지나요? 2 중
6. 카이제곱 분포의 평균은 무엇과 같나요? 1 중
7. 카이제곱 분포의 분산은 무엇과 같나요? 1 중
8. 총변동은 무엇으로 구성되나요? 1 중
9. 분산분석(ANOVA)에서 처리제곱합($SS_T$)은 무엇을 설명하나요? 1 중
10. 분산분석(ANOVA)에서 오차제곱합($SS_E$)은 무엇을 설명하나요? 2 중