
본 프로젝트의 목적은 가상 딸기의 속성을 표현하는 확률모델과 통계모델을 통해 데이터셋을 생성하고, 이를 통해 “p값으로 가설을 검정하는 실습 루틴”을 개발하는 것입니다. 가상의 딸기 품종을 설과 아키로 명명하고, 딸기의 속성을 원인변수와 결과변수로 구분했습니다. 당도는 딸기의 상품가치를 나타내며, 결과변수로 정규분포를 따르는 연속형 확률변수로 모델링되었습니다. 품종, 출하월, 저온숙성이 당도의 원인변수로 선정되었습니다. 과중은 당도의 원인이 아니며 당도와 과중은 성숙일과 관련이 있습니다. 여러 가설을 검정하기 위해 대응표본 t검정, 독립표본 t검정, 일원분산분석 F검정을 사용했습니다. 각각의 가설은 저온숙성이 당도를 높이는가, 품종에 따라 당도가 다른가, 출하월에 따라 당도가 다른가를 검토했습니다. 설과 아키의 속성 모델로 모집단을 생성하고 표본을 추출하여 가설검정을 수행했습니다. 프로젝트 결과, 데이터셋 생성 및 가설검정 프로그램이 제작되었으며, 각각 “데이터 논문”과 “학습 논문”으로 발표되었습니다.
본 프로젝트는 상품가치의 관점에서 관측할 딸기의 속성을 정하고 상품가치를 평가하는 속성을 관심있는 결과변수로 하여 그 결과변수의 원인이 되는 변수를 찾는 능력을 배양하기 위한 실습 루틴을 개발하는 프로젝트입니다. 따라서 본 프로젝트에서는 가상의 딸기를 표현하는 확률모델과 통계모델을 통해 데이터셋을 생성하고, 표본추출을 통해 “p값으로 가설을 검정하는 실습 루틴”을 개발하기 위함입니다. 본 프로젝트에서는 가상의 딸기 품종을 설과 아키로 명명하였습니다.
딸기의 속성을 나타내는 데이터 프레임을 정하고 속성을 원인변수와 결과변수로 구분하였습니다. 당도는 딸기의 상품가치를 표현하는 대표적인 딸기의 속성입니다. 본 프로젝트에서는 결과변수인 당도를 정규분포를 나타내는 연속형 확률변수로 모델링하였습니다. 당도의 변동을 일으키는 원인변수로는 품종, 출하월, 저온숙성을 선정하였습니다.
과중은 당도 생성의 원인이 아닙니다. 따라서 당도와 과중의 상관과 회귀는 원인과 결과를 표현하지는 않습니다. 통계모델을 이용하여 당도와 과중 생성의 근본 원인인 성숙일의 확률분포와 당도와 과중과의 관계를 찾는 프로젝트입니다. 성숙일과 선형 관계가 있는 출하연속월수와 당도와 과중의 상관과 회귀를 분석하는 프로젝트입니다.
성숙일은 개화일부터 수확일까지의 날짜로 정하였습니다. 수확은 딸기가 최고로 익은날(전체가 붉은색을 띠는 날) 수확하는 것으로 하였고 이때 당도가 최고라고 모델링하였습니다. 이 모델에서는 수확일이 과중이 제일 큰 시기인지는 알 수 없습니다. 수확일까지 당도는 선형적으로 증가하나, 성숙일 동안 과중이 더 증가하지 않는 구간이 있을 수 있습니다. 딸기의 상품가치는 과중보다 당도에 더 따른다고 가정하여 수확일을 결정하였습니다. 성숙일은 품종별로 출하월과 관계를 가진다고 보았습니다.
당도가 딸기의 상품가치를 나타냄을 고려하여 소비자 측면에서 당도에 대한 3가지 가설을 수립하였습니다. 첫째는 ‘저온숙성은 딸기의 당도를 높이는가’, 둘째는 ‘품종에 따라 당도는 다른가’, 세째는 ‘출하월에 따라 당도는 다른가’입니다. 각각의 가설을 검정하기 위하여 대응표본 t검정, 독립표본 t검정, 일원분산분석 F검정을 행하였습니다.
우선, 가상의 딸기 품종인 설(Seol)과 아키(Aki)의 속성의 생성 모델을 만들어 각 품종 당 출하월별 1000개의 크기를 가지는 모집단(출하한 딸기, 생산한 딸기)을 생성하였습니다. 딸기의 상품가치를 평가하기 위하여 모집단에서 무작위로 표본크기 20의 표본을 추출하였습니다. 표본의 표본통계량을 관측하여 생성 모델의 모수와 비교하여 표본의 모집단에 대한 대표성을 살펴 보았습니다.
가설검정을 위한 대응표본 t검정, 독립표본 t검정, 일원분산분석 F검정의 p값을 구하여 가설을 판정하였습니다. 판정한 결과가 생성모델을 따르는 지를 검정하였습니다.
본 프로젝트를 통하여 데이터셋을 생성하는 프로그램과 가설을 검정하는 프로그램이 제작되었으며 데이터셋을 생성하는 프로그램과 확률모델은 “데이터 논문”으로 발표되었습니다. 가설을 검정하는 프로그램과 적합성이 검정되어 모집단을 대표할 수 있는 표본데이터는 “학습 논문”으로 발표되었습니다.
딸기의 품종은 매우 다양하며, 각 품종은 고유의 특성, 맛, 크기, 재배 조건 등을 가지고 있습니다.
딸기의 출하는 딸기가 가장 잘 익었을 때 수확하여 행해집니다. 따라서, 출하시에 당도가 최고라고 할 수 있습니다. 하우스 재배에서는 겨울부터 봄까지 출하됩니다. 이 프로젝트에서는 12월, 다음해 1월, 2월, 3월, 4월에 딸기가 출하된다고 모델링하였습니다. 그리고 명목형 변수인 출하월을 연속형 변수로 바꾸기 위하여 1, 2, 3, 4, 5로 대치하였습니다.[표 1] 기온이 낮을 때 성숙일이 길어져서 당도가 높아지기 때문에 재배하우스의 경제적인 기온과 조사일수, 재배하는 딸기 품종을 고려하여 출하월을 정하였습니다.
딸기의 성숙일은 딸기가 꽃을 피운 후 완전히 익어 당도가 최고로 되는 기간인 성숙기를 날짜로 표현한 수치입니다. 성숙일은 일조시간이 길수록 기온이 낮을 수록 길어집니다. 따라서 일년중 수확하는 달에 따라 성숙일은 달라집니다. 가상 딸기에서는 성숙일이 딸기의 품종과 관계없이 같다고 보았습니다. 비닐하우스에서 딸기의 개화일은 파종후 2개월에서 3개월 사이에 있다고 보았습니다. 개화월로부터 출하월까지의 성숙일은 재배하우스의 기온과 조사일수에 따라 결정된다고 보았습니다. 개화월은 11월에 집중되도록 파종하여 딸기의 품종에 따라 성숙일이 출하월인 12월과 다음해 1월, 2월, 3월, 4월에 걸쳐 선형적으로 증가한다고 모델링하였습니다.
딸기의 저온 숙성은 주로 0°C에서 4°C 사이의 온도에서 이루어집니다. 딸기를 저온에서 숙성하면 당도가 증가합니다. 이는 저장 과정에서 당분이 축적되고 산도가 감소하기 때문입니다.
딸기의 당도는 딸기의 맛과 품질을 결정하는 중요한 요소입니다.
과중은 딸기의 시장성을 평가하는 중요한 지표입니다.
Table 1. 출하월과 변환데이터
| 변수 | 출하월 | ||||
|---|---|---|---|---|---|
| 12월 | 다음해 1월 | 다음해 2월 | 다음해 3월 | 다음해 4월 | |
| 출하연속월수 | 1 | 2 | 3 | 4 | 5 |
| 성숙일 | 40 | 38 | 36 | 34 | 32 |
1) 성숙일
성숙일은 출하연속월수에 따라 정규분포를 나타낸다고 모델링하였습니다. 그리고 출하연속월수가 정수일 때 구간을 나타낸다고 하면 구간의 성숙일의 대표값은 중앙값으로 표현하였습니다.[표 1]
2) 과중과 당도
출하한 딸기의 과중과 당도의 분포는 성숙일의 분포와 동일하기 때문에 출하한 딸기의 확률분포는 정규분포를 나타냅니다.
1) 대응표본(P1-1)
원인변수는 저온숙성: 저온숙성 유무는 당도의 변동성을 일으키는 이분형 원인변수
결과변수는 당도: 당도는 저온숙성 처리에 따르는 결과변수
2) 독립된 집단이 2개인 독립표본(P1-2)
집단명은 품종이라는 범주형 변수로 구분되는 설과 아키
원인변수는 품종: 품종은 당도의 변동의 원인이 되는 범주형 원인변수
결과변수는 당도: 당도는 품종에 따라 달라지는 결과변수
3) 독립된 집단이 5개인 독립표본(P1-3)
집단은 출하월이라는 범주형 변수에 의해 구분되며 범주형 원인변수의 변수명은 12월, 다음해 1월, 2월, 3월, 4월
원인변수는 품종: 품종일은 당도의 변동성을 나타내는 범주형 원인변수
결과변수는 출하월: 당도는 출하월에 따라 달라지는 결과변수
1) 성숙일과 당도의 단순선형회귀
설명변수는 성숙일: 성숙일은 당도를 대부분 설명할 수 있는 설명변수
반응변수는 당도: 당도는 성숙일에 반응하는 반응변수
2) 성숙일과 과중의 단순선형회귀
설명변수는 성숙일: 성숙일은 과중을 대부분 설명할 수 있는 설명변수
반응변수는 과중: 과중은 성숙일에 반응하는 반응변수
1) 과중과 당도의 상관모델(P1-4)
당도와 과중은 성숙일에 의해 단순선형회귀모델로 생성되는 속성이며, 따라서 당도와 과중은 선형상관모델로 표현할 수 있습니다. 즉, 당도와 과중은 상관관계를 가지는 변수입니다.
2) 과중과 당도의 선형회귀모델(P1-5)
과중에는 용액이 포함되며 또한 용액에는 당분이 포함됩니다. 당도는 용액에서 당분이 차지하는 비율입니다. 그리고 과중과 당도는 성숙일에 선형성을 나타내므로 두 변수는 선형관계를 나타냅니다. 과중과 당도의 관계는 과중을 원인변수로 당도를 결과변수로 하는 선형회귀모델로 표현할 수 있습니다. 즉, 과중을 설명변수로 당도를 설명변수로 하는 선형회귀모델이 나타납니다.
1) 품종에 따른 등급의 확률분포 모델(P1-6)
품종에 대해 당도의 확률분포는 독립적으로 생성되므로 당도로 정해지는 등급의 확률분포는 품종에 따라 다른 독립성을 나타냅니다.
2) 출하월에 따른 등급의 확률분포 모델
같은 품종에서 출하월에 대해 당도의 확률분포는 동일하게 나타납니다.
1) 출하월
관측이 어려운 성숙일 대신 출하월을 관측하였습니다. 출하월은 12월 부터 다음 해 4월까지 5개의 출하월로 하였습니다. 범주형 변수인 출하월을 연속형 변수로 변환한 출하연속월수를 도입하였습니다. 출하월에 대응하는 성숙일을 정하고 성숙일대신 출하월을 관측하는 것으로 하였습니다.
2) 품종
3) 당도
4) 과중
1) 저온숙성
저온숙성을 딸기의 생성 후 당도를 변화시키는 원인변수로 하였습니다. 품종에 따라 반응이 다르다고 모델링하였습니다.
Table 2. 가상 딸기 속성의 모델링과 표기
| 속성과 모델링 | 가상 딸기의 속성 | |||||
|---|---|---|---|---|---|---|
| 품종 | 성숙일 | 출하연속월수 $\leftarrow$ 출하월 | 저온숙성 | 당도 | 과중 | |
| 모델링 | 품종에 따라 성숙일이 다르다. | 성숙일은 정규분포를 나타낸다. | 1$\leftarrow$ “12월” 2$\leftarrow$ “다음해 1월” 3$\leftarrow$ “다음해 2월” 4$\leftarrow$ “다음해 3월” 5$\leftarrow$ “다음해 4월” | 품종에 따라 저온숙성에 대한 반응이 다르다. | 성숙일과 과중은 선형상관 관계를 나타낸다. 단순선형회귀 모델에서는 품종에 따라 회귀직선의 기울기가 다르다. 절편은 0이다. | 성숙일과 과중은 선형상관 관계를 나타낸다. 단순선형회귀 모델에서는 품종에 따라 회귀직선의 기울기가 다르다. 절편은 0이다. |
| 관측방법 | 파종시 관측 | 관측어려움 | 출하월은 출하시 관측, 출하연속월수는 출하월에서 변환 | 저온숙성 처리 유무 | 브릭스 당도계로 측정 | 저울로 측정 |
| 데이터 종류 | 범주형 명목척도 | 연속형 비례척도 | 연속형 간격척도 | 이분형 순서척도 | 연속형 비례척도 | 연속형 비례척도 |
| 모델 변수 | 원인변수 | 원인변수 | 원인변수 | 원인변수 | 결과변수 | 결과변수 |
| 확률변수 표기 | $^1X$ | $^2X$ | $^3X$ | $^4X$ | $^1Y$ $^1_1 Y$: 설품종의 당도 $^1_2Y$: 아키품종의 당도 | $^2Y$ $^2_1 Y$: 설품종의 과중 $^2_2Y$: 아키품종의 과중 |
| 변수값 표기 | $^1x$ | $^2x$ | $^3x$ | $^4x$ | $^1y$ $^1_1y$: 설품종의 당도값 $^1_2y$: 아키품종의 당도값 | $^2y$ $^2_1y$: 설품종의 과중값 $^2_2y$: 아키품종의 과중값 |
표본의 관측값 표기 (i번째 집단, j번째 개체) | $^1x_{ij}$ | $^2x_{ij}$ | $^3x_{ij}$ | $^4x_{ij}$ | $^1y_{ij}$ | $^2y_{ij}$ |
가상 딸기의 품종($^1X$)은 범주형 변수이고 변수값은 $\text{Seol}$과 $\text{Aki}$입니다.
$$^1x=\{\text{Seol, Aki}\}=\{1,2\}$$
여기서, $^1x$는 가상 딸기의 품종의 집합명이고 범주형 변수
설(Seol)은 가상 딸기 품종명: $\text{Seol}=1$
아키(Aki)는 가상 딸기 품종명: $\text{Aki}=2$
출하연속월수와 출하월의 관계식
$$^3x = (\text{출하월} – 11)\cdot\mod 12 + 1
$$
여기서, $^3 x$는 출하연속월수: 1이상 5이하 정수
따라서, 12월이면 $^3 x=1$, 다음해 1월이면 $^3 x=2$, 다음해 2월이면 $^3 x=3$, 다음해 3월이면 $^3 x=4$, 다음해 4월이면 $^3 x=5$
성숙일($^2x$)은 연속형 원인변수이고 출하월(수확월)과 관계있고 출하연속월수와 선형관계에 있다고 모델링하였습니다.
$^2x=42-2\cdot{^3x}$
여기서, $^2x$은 성숙일: 성숙일은 0과 양의 실수
$^3x$는 출하연속월수: $^3x=\{1,2,3,4,5\}$
성숙일은 정규분포를 가진다고 모델링하여 성숙일 데이터를 생성합니다.
$$^2X \sim N(\mu_{^2X}, \sigma_{^2X}^2) $$
여기서, $^2X$는 성숙일: 성숙일은 0과 양의 실수
$\mu_{^2X}$는 성숙일의 모평균
$\sigma_{^2X}^2$은 성숙일의 모분산
성숙일($^2x$)에 따른 당도($^1y$)의 선형회귀 모델
$$^1y=\beta_{0,^1Y}+\beta_{1,^1Y}{\cdot} {^2x}+\epsilon_{^1Y}$$
여기서, $^1y$는 당도
$\beta_{0,^1Y}$는 회귀직선의 절편이며 값이 0
$\beta_{1, ^1Y}$는 회귀직선의 기울기
$\epsilon_{^1Y}$은 오차항이며 평균이 0이고 분산이 $\sigma_{^1Y}^2$인 정규분포: $\epsilon_{^1Y} \sim N(0, \sigma_{^1Y}^2)$
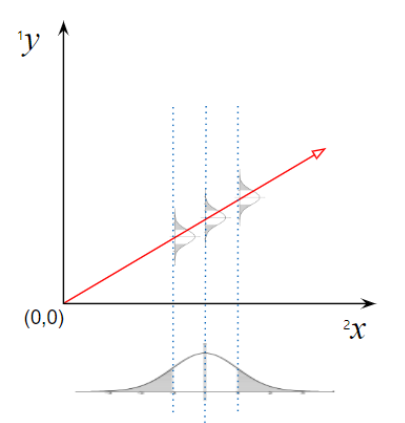
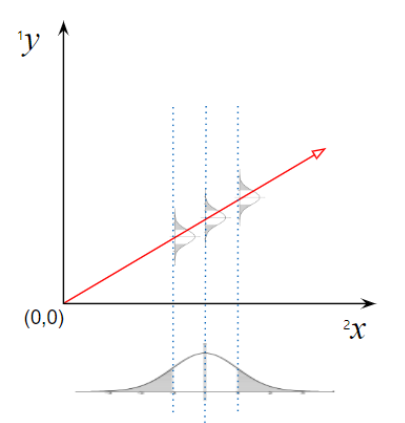
Figure 1. 성숙일에 따른 당도의 회귀
성숙일($^2x$)과 과중($^2y$))의 선형회귀 모델
$$^2y=\beta_{0,^2Y}+\beta_{1,^2Y}{\cdot} {^2x}+\epsilon_{^2Y}$$
여기서, $^2y$는 과중
$\beta_{0,^2Y}$는 회귀직선의 절편이며 값이 0
$\beta_{1, ^2Y}$는 회귀직선의 기울기
$\epsilon_{^2Y}$은 오차항이며 평균이 0이고 분산이 $\sigma_{^2Y}^2$인 정규분포: $\epsilon_{^2Y} \sim N(0, \sigma_{^2Y}^2)$
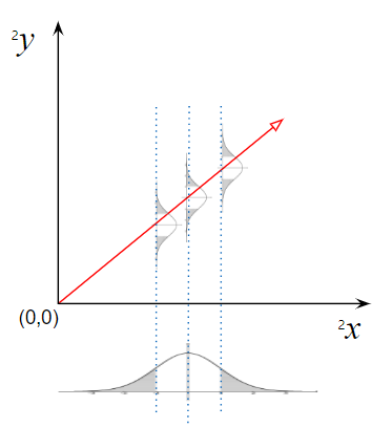
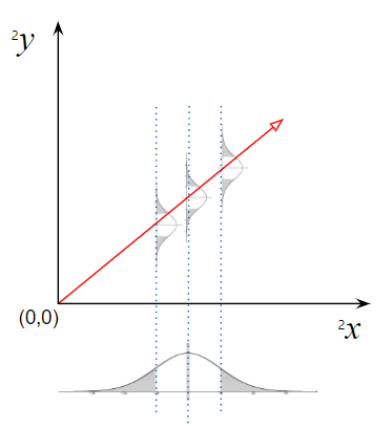
Figure 2. 성숙일에 따른 과중의 회귀
당도($^1Y$)와 과중($^2Y$)의 상관회귀 모델 유도
$$\dfrac{^1y-\epsilon_{^1Y}}{^2y-\epsilon_{^2Y}}=\dfrac{\beta_{1,^1Y}}{\beta_{1,^2Y}}$$
$$\therefore {^1y}=\dfrac{\beta_{1,^1Y}}{\beta_{1,^2Y}}{\cdot}{^2y}+\epsilon_{^1Y}-\dfrac{\beta_{1,^1Y}}{\beta_{1,^2Y}}\epsilon_{^2Y}$$
여기서, $^1y$은 당도
$\dfrac{\beta_{1,^1Y}}{\beta_{1,^1Y}}$은 과중에 대한 당도의 회귀직선의 기울기
$\epsilon_{^1Y}-\dfrac{\beta_{1,^1Y}}{\beta_{1,^2Y}}\epsilon_{^2Y}$은 오차항이며 평균이 0이고 분산이 $\sigma_{^1Y}^2+\left(\dfrac{\beta_{1,^1Y}}{\beta_{1,^2Y}}\right)^2 \cdot \sigma_{^2Y}^2$인 정규분포를 나타냄
과중에 대한 당도의 회귀직선의 기울기와 과중과 당도의 상관계수 그리고 과중과 당도의 표준편차의 관계식
$$\dfrac{\beta_{1,^1Y}}{\beta_{1,^2Y}}=\rho_{^1Y^2Y}\dfrac{\sigma_{^1Y}}{\sigma_{^2Y}}$$
여기서, $\rho_{^1Y^2Y}$는 당도($^1Y$)와 과중($^2Y$)의 상관계수
$\sigma_{^1Y}$는 당도의 표준편차
$\sigma_{^2Y}$는 과중의 표준편차
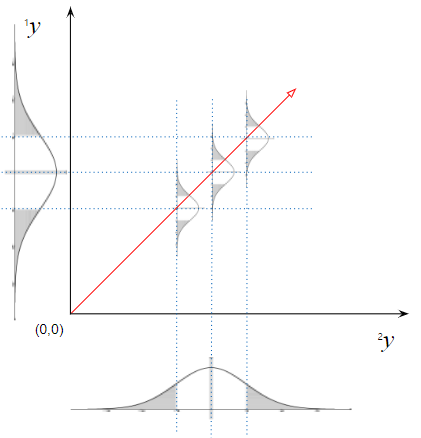
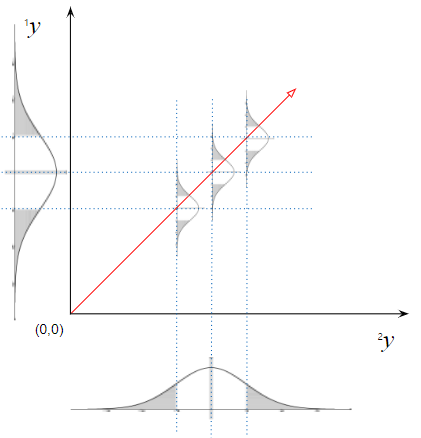
Figure 3. 설과 아키의 과중-당도 상관회귀
출하연속월수에 따른 당도의 선형회귀모델
$$^1y=\beta_{0}+\beta_{1}{\cdot}{^3x}+\epsilon_{^1Y}$$
여기서, $^1y$는 당도값
$^3x$는 출하연속월수의 값
$\beta_{0}$은 회귀직선의 절편
$\beta_{1}$은 회귀직선의 기울기
$\epsilon_{^1Y}$은 오차항이며 평균이 0이고 분산이 $\sigma_{^1Y}^2$인 정규분포를 나타냄: $\epsilon \sim N(0, \sigma_{^1Y}^2)$
저온숙성 전후 대응된 딸기 개체의 당도 대응표본 모델
$${^1y}_{2}={^1y}_{1}+\bar{D}+\epsilon_{D}$$
여기서, $^1y_{2}$는 저온숙성 후 개체의 당도
${^1y}_{1}$은 저온숙성 전 개체의 당도
$D$는 저온숙성 전후 당도차이이며 확률변수: $d={^1y}_{2}-{^1y}_{1}$, $D=\bar{D}+\epsilon_{D}$
$\bar{D}$는 저온숙성으로 인한 당도변화의 평균
$\epsilon_{D}$는 오차항이며 평균이 0이고 분산이 $\sigma_{D}^2$인 정규분포를 나타냄: $\epsilon_{D} \sim N(0, \sigma_{D}^2) $
성숙일($^2 x$)과 출하연속월수를 원인변수로 하는 당도($^1 y$)의 표본 모델의 예시는 다음과 같습니다.
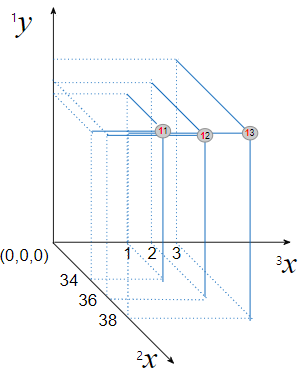
Figure 4. 성숙일과 출하연속월수를 원인변수로 하는 당도의 표본델
가상 딸기의 표본 모델을 위해 표본내의 집단과 각 집단의 크기를 정합니다. 표본내 첫번째 집단을 1이라고 하고 집단의 크기가 3이라 할 때 출하연속월수($^3 x$)와 당도($^1 y$)의 2차원 좌표계에서 딸기 데이터 포인트의 산점도의 예시는 다음과 같습니다.
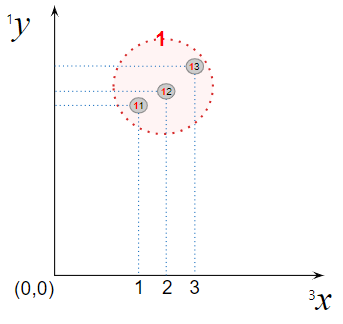
Figure 5. 딸기의 출하연속월수와 당도를 표현한 산도
Table 3. 데이터 생성 모델 매개변수
| 변수 | 생성 모델 | 품종($^1 x$) 별 생성모델 매개변수값 | |
|---|---|---|---|
| 설(Seol) | 아키(Aki) | ||
성숙일 $(^2x)$ | $$^2X \sim N(\mu_{^2X}, \sigma_{^2X}^2) $$ 여기서, $^2X$는 성숙일: 성숙일은 0과 양의 실수 $\mu_{^2X}$는 성숙일의 모평균 $\sigma_{^2X}^2$은 성숙일의 모분산 | ${^2X} \sim N(36, 2^2)$ 위의 정규분포를 5개의 구간으로 나누어 각 구간의 누적확률밀도로 수준(level)의 크기를 정하고 각 구간의 중앙값을 수준(level)의 값으로 정함. $P({^2X}) = | |
저온숙성 $(^4x)$ | $${^1y}_{2}={^1y}_{1}+\bar{D}+\epsilon_{D}$$ 여기서, ${^1y}_{2}$는 저온숙성 후 개체의 당도 ${^1y}_{1}$은 저온숙성 전 개체의 당도 $D$는 저온숙성 전후 당도차이이며 확률변수: $d={^1y}_{2}-{^1y}_{1}$, $D=\bar{D}+\epsilon_{D}$ $\bar{D}$는 저온숙성으로 인한 당도변화의 평균 $\epsilon_{D}$는 오차항이며 평균이 0이고 분산이 $\sigma_{D}^2$인 정규분포를 나타냄: $\epsilon_{D} \sim N(0, \sigma_{D}^2) $ | $_1\bar{D}=0.20$ $\sigma_{_1D}^2=0.10^2$ | $_2\bar{D}=0.10$ $\sigma_{_2D}^2=0.10^2$ |
당도 $(^1y)$ | $$^1y=\beta_{0,^1Y}+\beta_{1,^1Y}{\cdot} {^2x}+\epsilon_{^1Y}$$ 여기서, $^1y$는 당도 $\beta_{0,^1Y}$는 숙성일에 대한 당도의 회귀직선의 절편이며 값이 0 $\beta_{1, ^1Y}$는 숙성일에 대한 당도의 회귀직선의 기울기 $\epsilon_{^1Y}$은 오차항이며 평균이 0이고 분산이 $\sigma_{^1Y}^2$인 정규분포: $\epsilon_{^1Y} \sim N(0, \sigma_{^1Y}^2)$ | $\beta_{1, ^1_1Y}=0.30$ $\sigma_{^1_1Y}^2=0.25^2$ | $\beta_{1, ^1_2Y}=0.25$ $\sigma_{^1_2Y}^2=0.50^2$ |
과중 $(^2y)$ | $$^2y=\beta_{0,^2Y}+\beta_{1,^2Y}{\cdot} {^2x}+\epsilon_{^2Y}$$ 여기서, $^2y$는 과중 $\beta_{0,^2Y}$는 성숙일에 대한 과중의 회귀직선의 절편이며 값이 0 $\beta_{1, ^2Y}$는 성숙일에 대한 과중의 회귀직선의 기울기 $\epsilon_{^2Y}$은 오차항이며 평균이 0이고 분산이 $\sigma_{^2Y}^2$인 정규분포: $\epsilon_{^2Y} \sim N(0, \sigma_{^2Y}^2)$ | $\beta_{1, ^2_1Y}=0.60$ $\sigma_{^2_1Y}^2=0.25^2$ | $\beta_{1, ^2_2Y}=0.50$ $\sigma_{^2_2Y}^2=0.25^2$ |
데이터 집합에서 데이터포인트(data point)의 변동(variation)은 집합의 분산(variance) 또는 표준편차(Standard Deviation)로 수치화합니다. 따라서 표본내 개체(individual)의 변동은 표본의 통계량인 분산과 표준편차로 표현할 수 있습니다.
정리하면 집합의 데이터가 평균과 얼마나 다른지를 표준편차와 분산을 측정하여 데이터 집합의 변동성을 수치로 표현합니다.
표본내에 독립된 여러 집단(group)이 있는 경우, 어떤 원인에 의해 집단의 변동이 나타날 수 있습니다. 표본내 집단의 변동은 각 집단의 평균과 그 집단의 자유도의 곱의 합으로 표현할 수 있습니다. 집단의 변동성이 크면 변동은 크게 나타납니다.
표본내 집단의 변동과 개체의 변동이 합해져서 표본의 총변동이 됩니다. 집단과 개체의 변동을 비교하여 집단의 변동성을 분석하는 방법을 분산분석(ANOVA: Analysis of Variance)이라고 합니다. 집단의 변동성을 신호(signal)라고 한다면 개체의 변동성은 노이즈(noise)라고 할 수 있습니다.
분산분석에서는 집단내변동과 집단간변동을 비교하여 집단의 변동성(Variation)을 평가합니다. 즉, 노이즈의 변동성에 대해 신호의 변동성이 얼마나 더 잘 나타나는 가를 평가합니다.
총변동(Total Variation)은 전체 데이터의 변동성을 표현하며 집단간변동과 집단내변동의 합입니다.
집단간변동(Between-group Variation)은 각 집단의 평균이 전체 평균으로부터 벗어난 정도입니다. 표본내 집단간변동을 표본내 집단의 자유도로 나누면 표본내 집단간분산이 됩니다.
집단내변동(Within-group Variation)은 각 집단 내부의 데이터포인트가 그 집단의 평균으로부터 벗어난 정도입니다. 표본내 각 집단의 집단내변동을 각 집단의 자유도로 나눈 각 집단의 분산을 합하면 집단내분산이 됩니다.
표본의 분산분석은 집단내분산에 대한 집단간분산의 비입니다. 따라서 분산분석은 집단의 변동성을 여러 집단의 평균 차이가 통계적으로 유의미한가로 평가하는 방법입니다.
대응표본은 개체가 서로 대응되어 있는 표본입니다. 표본내 두 집단이 대응되어 있다고 표현할 수도 있습니다. 대응표본의 새로운 확률변수는 대응된 두 집단의 개체의 속성값의 차이입니다. 대응표본은 원인에 대한 결과변수의 반응을 추적하는 데 용이합니다. 반응은 차이의 평균과 분산으로 표현할 수 있는 데 반응은 평균으로 노이즈는 분산으로 모델링할 수 있습니다.
저온숙성의 효과는 노이즈인 차이의 표준편차와 저온숙성의 신호인 차이평균의 비로 검정할 수 있습니다.
원인변수인 저온숙성에 대해 반응은 그 위치에서의 미분계수(기울기)로 나타납니다. 여기서 미분계수는 수치화되어 있으므로 그 점에서 반응의 수치화라고 할 수 있습니다. 반응의 결과로 결과변수의 새로운 확률변수인 당도의 차이가 발생합니다. 차이가 없으면 차이의 값은 0입니다. 그리고 차이는 음과 양의 값을 가지는 편차입니다. 저온숙성 전후 딸기의 당도의 차이가 새로운 변수입니다.
원인변수에 따른 반응에 따라 선형상관이 발생(회귀직선의 회전)하거나 회귀직선의 이동이 발생합니다. 보통 2가지 현상이 같이 나타납니다. 표본의 회수를 늘려서 회귀선(또는 회귀면)을 살펴보면 큰 수의 법칙에 따라 모회귀선에 가까워짐을 관찰할 수 있습니다. 즉, 표본의 대표값 집합인 회귀선, 또는 회귀면이 모회귀선과 같아 지는 데, 이 현상을 회귀(regression)라고 부릅니다.
저온숙성 전과 저온숙성 후의 분산은 변함이 없다고 가정합니다. 이를 등분산가정이라고 부릅니다. 등분산가정은 연속적인 반응이 일어남에 있어 속성의 공간에서 출현하는 데이터는 방향에만 영향을 준다는 중요한 가정입니다.
만일, 저온숙성 전의 당도의 값에 따라 차이가 달라진다면 저온숙성 전후 등분산가정이 성립되지 않으며 저온숙성 후 분산이 증가하게 됩니다. 다시 말하면 저온숙성은 저온숙성 전의 당도의 값에 영향을 받지 않는 다는 의미입니다.
차이의 평균과 분산은 동시에 구해 집니다. 차이의 평균은 저온숙성의 효과입니다. 차이의 제곱합은 저온숙성에 의한 표본의 총변동입니다. 등분산가정이 있다면 차이평균의 연속적인 변화도 관측할 수 있습니다.
독립표본은 표본내 집단이 독립되어 있다는 뜻입니다. 표본내 집단이 1개이면 단일표본이라합니다. 표본내 집단이 두 개이고 개체가 대응되어 있으면 대응표본이고 대응되어 있지 않으면 독립표본이라고 부릅니다. 딸기의 품종은 서로 독립된 집단이라고 할 수 있습니다. 두 품종에 동시에 속하는 분류는 하지 않기 때문입니다. 표본내 집단이 2개이고 등분산가정을 하면 대응표본의 기준이 될 수 있습니다. 독립되어 있다는 것은 공분산이 0이 됨을 의미하기 때문입니다. 따라서 표본내 2개의 집단이 있는 경우, 대응표본의 기준으로 독립표본으로 검정을 하면 심도있는 분석을 할 수 있습니다. 표본내 3개 이상의 집단이 있는 경우는 집단간분산과 집단내분산을 비교하여 신호와 노이즈의 강도를 비교할 수 있습니다.
성숙일에 대한 당도의 기울기, 즉, 일조량에 따른 반응정도에 따라 품종이 결정된다고 가정하였다. 따라서 출하월의 당도의 두 품종의 확률분포를 통한 t검정을 수행하여 품종이 다름을 확인하고자 하였습니다. 주어지는 유의수준은 95%로 하였습니다.
출하월에 따라 당도가 다름을 일원분산분석으로 검정하고자 하였습니다. 원인변수인 출하월은 1달이므로 충분한 차이가 있고 당도의 차이가 확실한 출하월의 구간을 알고자 하였습니다. 이는 성숙일과 품종에 따라 관계가 있을 것입니다.
당도와 과중은 성숙일을 원인변수로 공유하고 있기 때문에 딸기의 당도와 과중은 상관의 유의성이 나타날 것입니다. 당도과 과중의 성숙일에 대한 오차항의 분산으로 당도와 과중의 상관계수를 구할 수 있습니다. 당도와 과중은 원인과 결과의 관계가 아님에도 상관의 유의성은 있습니다. 상관분석 t검정을 수행하였으며 유의성의 기준으로 유의수준을 정할 것입니다.
성숙일에 대한 당도와 과중은 회귀선을 평균으로 하고 오차항의 분산을 분산으로 하는 확률분포를 나타낸다고 할 때, 당도와 과중의 회귀직선의 적합성은 당도와 과중의 공분산과 관련됩니다. 당도와 과중이 독립이라면 당도와 과중의 회귀직선은 적합하지 않지만 공분산이 최고가 되는 당도와 과중의 표준편차의 곱에서 회귀직선의 적합성은 최대가 됩니다. 여기서 당도와 과중의 공분산을 주어서 데이터 생성을 하였고 공분산의 값에 따라 회귀직선의 적합성이 결정됩니다. 단순선형회귀분석 F검정을 수행하였으며 유의수준을 정할 것입니다.
같은 품종이라는 것을 판정하는 방법에는 출하월에 따른 확률분포의 매개변수가 같음으로 판정하는 방법이 있습니다. 즉, 출하월에 따라 당도의 확률분포가 같다면 순종의 품종이라고 할 수 있습니다.