
통계량을 통한 모수 추정에서, 확률변수의 모평균, 모분산, 모표준편차는 각각 표본평균, 표본분산, 표본표준편차를 통해 추정됩니다. 상관분석은 두 변수 간의 선형적 관계를 측정하며, 피어슨상관계수는 이 관계의 강도와 방향을 수치화합니다. 공분산은 두 변수 간의 변동성을 나타내며, 상관계수는 공분산을 표준화한 값입니다. 상관계수의 제곱인 결정계수는 변수 간 관계의 적합도를 평가합니다. 표본상관계수의 표준오차와 검정통계량을 이용해 상관관계의 유의성을 검정할 수 있습니다.
단순선형회귀(simple linear regression)는 설명변수(독립변수, 예측변수, factor, 요인변수)가 연속형인 경우의 변수간의 관계입니다. 설명변수는 반응변수(종속변수, 결과변수)의 반응을 설명하는 변수입니다. 단순선형회귀의 예는 다음과 같습니다.
– 딸기의 과중(설명변수)과 당도(반응변수)
– 학생의 키(설명변수)와 몸무게(반응변수)
– 인간의 혈압(설명변수)과 기대수명(반응변수)
여기서 “딸기”, “학생”, “인간”으로 명명된 개체(요소)들은 2개의 속성를 가지고 있다고 볼 수 있습니다. 이 속성의 관계를 모델링하여 하나의 속성으로 다른 속성을 추론합니다. 속성은 변수로 모델링됩니다. 그리고 중요한 것은 회귀분석을 하기 위해서는 반응변수를 확률변수로 규정하여야 한다는 것입니다.
당도를 $Y$좌표로 과중을 $X$좌표로 하는 딸기의 점(point)들을 2차원 $XY$직각좌표계에 표시하면 산점도(scatter plot)가 됩니다. 여기서 당도를 종속변수(반응변수)라하고 과중을 독립변수(설명변수, 예측변수)라합니다. 산점도의 점들이 한 직선에 모이는 경향을 보이고 그 직선의 식을 추정할 수 있다면 딸기의 과중을 보고 당도를 예측할 수 있게 됩니다. 더 나아가 예측의 정확도도 제시할 수 있습니다. 이러한 예측을 위해서 회귀직선을 구하고 예측의 정확도를 제시하기 위하여 회귀직선의 분포를 구합니다.
직선상의 실현값(점, point)들을 대표하는 것에는 평균이 있습니다. 평균의 개념을 직선상에서 평면으로 확장하면 평면상의 실현값(점, point)들을 대표하는 것은 회귀선이라고 할 수 있습니다. 회귀선 중에서 선형성(선형회귀)을 나타내는 것을 회귀직선이라고 합니다. 한편, 단순선형회귀모델에서는 회귀직선과의 편차(deviation)는 모집단에서는 오차(error)라고 부르고 표본에서는 잔차(residual)라고 부릅니다. 선형회귀모델에서 오차와 잔차를 나타내는 항을 오차항이라고 부릅니다.
단순선형회귀에서는 회귀직선이 확장된 개념의 평균과 같은 역할을 한다고 볼 수 있습니다. 단순선형회귀에서는 설명변수 $X$의 실현값 $X_i$로 인해 반응하는 확률변수인 $Y$의 실현값 $Y_i$는 회귀선상의 값을 평균으로 하는 확률분포를 나타낸다고 모델링합니다. 그리고 이 확률분포는 같은 정규분포를 가진다는 등분산가정을 합니다.
단순선형회귀는 $i$번째 실현된 $X_i$점에서의 반응확률변수 $Y_i$는 회귀선상의 평균을 가지고 모든 $i$에서 같은 분산을 가지는 정규분포를 나타냅니다.
단순선형회귀의 모집단모델의 예
$$Y_i=\beta_0+\beta_1{X_i}+\epsilon_i$$
여기서, $Y_i$는 딸기의 과중 $X_i$과 연관되어 실현된 당도이며 확률변수
$Y_i$의 조건부확률분포는 정규분포:
$y_i \mid x_i \sim N(\beta_0 + \beta_1 x_i, \sigma^2)$
$\epsilon_i$는 오차: $\epsilon_i\sim N(0, \sigma^2)$
단순선형회귀의 표본모델의 예
$$y_i = \hat{\beta}_0 + \hat{\beta}_1 x_i + e_i=\hat{y_i}+e_i$$
여기서, $y_i$는 딸기의 과중 $x_i$과 연관되어 관측된 당도이며 확률변수
$y_i$의 조건부확률분포는 정규분포:
$y_i \mid x_i \approx N(\hat{y_i}, \hat{\sigma}^2)$
$\hat{y_i}$는 예측값: $\hat{y}_i = \hat{\beta}_0 + \hat{\beta}_1 x_i$
$e_i$는 잔차: $e_i\sim N(0, \hat{\sigma}^2)$
Table 1. 오차와 잔차 비교
| 항목 | 오차 \( \epsilon_i \) | 잔차 \( e_i \) |
|---|---|---|
| 적용 | 모집단 선형회귀모델 $Y_i=\beta_0+\beta_1{X_i}+\epsilon_i$ | 표본 선형회귀모델 $y_i = \hat{\beta}_0 + \hat{\beta}_1 x_i + e_i$ |
| 정의 | \( \epsilon_i=y_i – (\beta_0 + \beta_1 x_i) \) | \( e_i=y_i – (\hat{\beta}_0 + \hat{\beta}_1 x_i) \) $$e_i = y_i – \hat{y}_i = (\beta_0 + \beta_1 x_i + \epsilon_i) – (\hat{\beta}_0 + \hat{\beta}_1 x_i)$$ \[ |
| 평균 | \( 0 \) | \( 0 \) |
| 분산 | 오차분산 \( \mathrm{Var}(\epsilon_i)=\sigma^2 \) | 잔차분산 \[ $h_{ii}$는 해트행렬 $\mathbf{H}$의 대각원소이며, 관측값 $i$의 영향력을 나타냄 $h_{ii}$는 관측값이 $y_i$의 회귀선을 당기는 힘. Hat matrix 정의 예측값($\hat{\mathbf{y}}$) 표현 |
| 분산 추정 | 오차분산 \[ | 오차분산의 추정량은 잔차 제곱합의 자유도 보정 평균 여기서, $MS_E$는 오차제곱평균(Mean Square Error) 잔차의 분산과 오차의 분산의 추정량은 다름 $$\mathrm{Var}(e_i) = \sigma^2(1 – h_{ii}) < \sigma^2$$ |
| 분포 | 정규분포 \( \epsilon_i \sim N(0, \sigma^2) \) | 정규분포로 근사 가능 \( e_i \sim N(0, \sigma^2(1-h_{ii}) \) |
| 계산 | 일반적으로 모름 | 표본에서 계산 가능 |
| 해석 | 모델의 이론적 오차 | 추정된 회귀선으로부터의 실제 오차 |
| 변수 | 확률변수 | 조건부확률변수: 추정량($\hat{\beta_0}$, $\hat{\beta_1}$)의 함수. 즉, 확률변수의 함수 |
| 제곱합 | 오차제곱합 (Sum of Squared True Errors) \[ $\epsilon_i$를 몰라서 계산불가 | 잔차제곱합 (Sum of Squared Residuals, $SS_{Res}$ or Sum of Squared Errors, $SS_E$) \[ 여기서, $SS_E$는 잔차제곱합 |
Table 1. 회귀 분석에서 오차 분산 및 추정량 요약
| 항목 | 분류 | 기호 | 설명 |
|---|---|---|---|
| 오차 분산 | 모수 | \( \mathrm{Var}(\epsilon_i) = \sigma^2 \) | 이론적 오차항의 분산으로, 직접 알 수 없음 |
| 오차 표준편차 | 모수 | \( \sigma = \sqrt{\mathrm{Var}(\epsilon_i)} \) | 오차항 분산의 제곱근 |
| 오차 분산 추정량 | 추정량 | \( \mathrm{Var}(e_i) \approx \hat{\sigma}^2 = \dfrac{1}{n – 2} \sum e_i^2 \) 또는 \( \sigma_{\text{Res}}^2 \) | MSE (Mean Square Error)로 불리며 오차 분산의 추정량 |
| 오차 표준편차 추정량 | 추정량 | \( \hat{\sigma} = \sqrt{\mathrm{Var}(e_i)} \) 또는 \( \sigma_{\text{Res}} \) | RMSE (Root Mean Square Error), 오차 표준편차의 추정값 |
$Y_i=\beta_0+\beta_1{X_i}+\epsilon_i$
$\bf{Y}{=}\bf{X}\boldsymbol{\beta}{+}\boldsymbol{\mathit{\epsilon}}$
$\bf{Y}=\left \lbrack{\begin{array}{c}{{Y}_{1}}\\{{Y}_{2}}\\{\vdots}\\{{Y}_{N}}\end{array}}\right \rbrack$, $\bf{X}=\left \lbrack{\begin{array}{cc}{1}&{{X}_{1}}\\{1}&{{X}_{2}}\\{\vdots}&{\vdots}\\{1}&{{X}_{N}}\end{array}}\right \rbrack$, $\boldsymbol{\beta}=\left \lbrack{\begin{array}{c}{{\beta}_{0}}\\{{\beta}_{1}}\end{array}}\right \rbrack$, $\boldsymbol{\epsilon}=\left \lbrack{\begin{array}{c}{{\epsilon}_{1}}\\{{\epsilon}_{2}}\\{\vdots}\\{{\epsilon}_{N}}\end{array}}\right \rbrack$
여기서, $i$는 $1,\ldots ,N$, $N \to \infty$
$N$은 모집단의 크기
$y_i=\hat{\beta_0}+\hat{\beta_1}{x_i}+e_i = \hat{y_i} + e_i$
$\bf{y}=\bf{X}\hat {\boldsymbol{\beta}}+\boldsymbol{e}$
$\bf{y}=\left \lbrack{\begin{array}{c}{{y}_{1}}\\{{y}_{2}}\\{\vdots}\\{{y}_{n}}\end{array}}\right \rbrack$, $\bf{X}=\left \lbrack{\begin{array}{cc}{1}&{{x}_{1}}\\{1}&{{x}_{2}}\\{\vdots}&{\vdots}\\{1}&{{x}_{n}}\end{array}}\right \rbrack$, ${\hat {\boldsymbol{\beta}}}=\left \lbrack{\begin{array}{c}{{\hat {\beta}}_{0}}\\{{\hat {\beta}}_{1}}\end{array}}\right \rbrack$, $\boldsymbol{e}=\left \lbrack{\begin{array}{c}{{e}_{1}}\\{{e}_{2}}\\{\vdots}\\{{e}_{n}}\end{array}}\right \rbrack$
여기서, $i$는 $1, …, n$
$n$은 표본크기
$\hat{\beta_1}=\dfrac{\sum\limits_{i=1}\limits^{n}(x_i{-}\bar{x})(y_i{-}\bar{y})}{\sum\limits_{i=1}\limits^{n}(x_i{-}\bar{x})^2}=\dfrac{SS_{XY}}{SS_X}=\dfrac{(n-1)s_{XY}}{(n-1)s_X^2}=\dfrac{s_{XY}}{s_X^2}$
여기서, $\bar x$는 확률변수 $X$의 표본평균: $\bar{x}=\dfrac{1}{n}\sum\limits_{i=1}^{n}{x}_i$
$\bar{y}$는 확률변수 $Y$의 표본평균 : $\bar{y}=\dfrac{1}{n}\sum\limits_{i=1}^{n}{Y}_i$
$SS_{XY}$는 확률변수 $X$와 $Y$의 공변동: $SS_{XY} = \sum_{i=1}^{n} (x_i – \bar{x})(y_i – \bar{y})$
$SS_X$는 확률변수 $X$의 총변동(제곱합): $SS_X = \sum_{i=1}^{n} (x_i – \bar{x})^2$
$s_{XY}$는 확률변수 $X$와 $Y$의 표본공분산 : $s_{XY}=\dfrac{\sum\limits_{i=1}^{n}(x_i-\bar{x})(y_i-\bar{y})}{n-1}$
$s_X^2$는 확률변수 $X$의 표본분산 : $s_X^2=\dfrac{\sum\limits_{i=1}^{n}(x_i-\bar{x})^2}{n-1}$
$n$은 표본크기
$\hat{\beta_0}=\bar{y}-\hat{\beta_1}\bar{x}$
여기서, $\hat{\beta_1}$는 표본회귀직선의 기울기
$\bar x$는 확률변수 $X$의 표본평균 : $\bar{x}=\dfrac{1}{n}\sum\limits_{i=1}^{n}{x}_i$
$\bar{y}$는 확률변수 $Y$의 표본평균 : $\bar{y}=\dfrac{1}{n}\sum\limits_{i=1}^{n}{y}_i$
$n$은 표본크기
Table 1. 단순선형회귀식 예시
| 변수 형태 | 의미 | 표기법 | 단순선형회귀모델 적용 |
|---|---|---|---|
| 확률변수 | 모집단에서 정의되는 이론적 변수 | 대문자: $X, Y$ | \(Y = \beta_0 + \beta_1 X + \epsilon\) |
| 실현값 | 표본에서 실제 관측된 값 | 소문자: $x, y$ | \(y_i = \hat{\beta}_0 + \hat{\beta}_1 x_i + e_i\) |
| 예측값 | 표본 데이터를 통해 얻어진 예측값 | hat+소문자: $\hat{x}, \hat{y}$ | \(\hat{y}_i = \hat{\beta}_0 + \hat{\beta}_1 x_i\) |
| 엄밀한 확률변수 | 이론적 정의로서의 예측값 | hat+대문자: $\hat{X}, \hat{Y}$ | \(\hat{Y}_i = \hat{\beta}_0 + \hat{\beta}_1 X_i\) |
| 확률변수 행렬 | 모집단에서 정의되는 이론적 행렬 | 행렬, 확률변수는 대문자 볼드체: $\mathbf{X}, \mathbf{Y}$ | \(\mathbf{Y} = \mathbf{X}\hat{\boldsymbol{\beta}} + \mathbf{e}\) |
| 실현값 행렬 | 여러 관측값을 행렬로 표현 | 행렬은 대문자 볼드체: $\mathbf{X}$, 벡터는 소문자 볼드체: $\mathbf{y}$ | \(\mathbf{y} = \mathbf{X}\hat{\boldsymbol{\beta}} + \mathbf{e}\) |
가정1) 집단의 단순선형회귀모델은 절편($\beta_0$)과 기울기( $\beta_1$)를 모수(parameter)로 가지는 선형(linear)모델이다.
집단이 모집단일 때 파생되는 표본의 단순선형모델은 표본절편($\hat{\beta_0}$)과 표본기울기( $\hat{\beta_1}$)를 통계량(statistic)으로 가지는 모델입니다.
– 모집단모델
$Y_i=\beta_0+\beta_1{X_i}+\epsilon_i$
여기서, $i=1, …,∞$
– 표본모델
$y_i=\hat{\beta_0}+\hat{\beta_1}{x_i}+e_i = \hat{y_i} + e_i$
여기서, $i=1, …,n$
$n$은 표본크기
가정2) 오차항($\epsilon_i$)의 기대값은 0이고 오차항은 회귀선을 중심으로 대칭으로 분포한다.
${\rm E}[\epsilon_i]$ = 0
가정3) 독립변수 $X_i$는 두 개 이상의 변수값을 가진다.
가정4) 독립변수 $X_i$는 비확률(nonstochastic)변수인 고정된 값일 수 있다.
다만, 이 경우 오차항의 기대값과 독립변수와 오차항의 공분산은 다음과 같은 조건을 만족해야 합니다.
${\rm E}[\epsilon_{i}] = 0$
${\rm E}[X_i\epsilon_{i}] = X_i$
가정5) 오차항($\epsilon_i$)은 모든 관측값 $i$에 대해 $\sigma^2$의 일정한 분산을 가진다.
관측시점에 관계없이($i$ 값에 관계없이) 오차항의 분산은 동일하다는 등분산(homoscedasticity)가정입니다. 이 때 각 독립변수($X$)의 값에 따른 종속변수($Y$)가 그 회귀직선을 중심으로 분포되어 있는 정도가 같습니다.
${\mathrm Var}[\epsilon_i]=σ^2$
${\mathrm E}[\epsilon_i^2]=σ^2$
가정6) 서로 다른 오차항은 선형적인 관계인 상관이 없다.
다만, 이는 오차항들이 서로 독립적임을 의미하지는 않습니다.( 오차항이 독립적일 경우에는 상관이 없다는 조건보다 더 강한 가정을 의미)
${\rm Cov}[\varepsilon_j,\varepsilon_k]=\mathrm{E}[\varepsilon_j\varepsilon_k]=0$
여기서, $j ≠ k$
가정7) 오차항은 정규분포를 따른다.
오차항이 정규분포를 따른다면, 추정된 회귀계수도 정규분포를 따르게 됩니다. 따라서 회귀계수의 추정값에 대한 표준오차(standard error)를 계산할 수 있고 검정통계량은 t분포 또는 F분포를 따르게 됩니다. 또한 최소제곱법과 최대우도법의 일치성이 보장됩니다.
$\epsilon_i \sim N(0,\sigma^2)$
“가정7) 오차항($\epsilon_i$)은 정규분포를 따른다”는 최소제곱법으로 구하는 추정량 (최소제곱추정량, Least Square Estimator, LSE)의 확률분포를 도출하기 위해 필요한 가정입니다.
$\epsilon_i\sim N(0,\hspace{0.33em}\sigma^2)$
“가정7) 오차항($\epsilon_i$)은 정규분포를 따른다”와 “가정2) 오차항($\epsilon_i$)의 기대값(평균)은 0 이다” 라는 두가지 가정으로 종속변수($Y$)도 정규분포를 나타냅니다.
$Y_i\sim N(\beta_0+\beta_1{X_i},\hspace{0.33em} \sigma^2)$
오차항의 모분산($\sigma_{Res}^2$)을 알 때, 최소제곱으로 구한 추정량 (Least Square Estimator, LSE)의 확률분포를 살펴봅니다. 가정 1) ~ 7)에 따라 최소제곱법(최소자승법, LSE)으로 구한 회귀계수의 추정량은 다음과 같은 정규분포를 가집니다.
$\hat{\beta}_1\sim N(\beta_1, \sigma_{\beta_1}^2)$
$\hat{\beta}_0\sim N(\beta_0,\sigma_{\beta_0}^2)$
여기서, $\sigma_{\beta_1}^2=\mathrm{Var}[\hat{\beta}_1] = \frac{\sigma^2}{\sum\limits_{i=1}^n (X_i – \bar{X})^2}$
$\sigma_{\beta_0}^2= \sigma^2 \cdot \left( \frac{ \sum X_i^2 }{ n \sum (X_i – \bar{X})^2 } \right)=\mathrm{Var}[\hat{\beta}_0] = \sigma^2 \left( \frac{1}{n} + \frac{\bar{X}^2}{\sum\limits_{i=1}^n (X_i – \bar{X})^2} \right)$
일치추정량 (consistent estimator)을 살펴보면, 표본크기가 무한히 커질 경우에 추정량의 분산값이 $0$에 근접함에 따라 추정량($\hat{\beta}_0$, $\hat{\beta}_1$)이 실제 모수($\beta_0$, $\beta_1$)에 수렴합니다. 이를 토대로 $\beta_0$와 $\beta_1$의 검증을 위해 표준정규분포를 이용할 수 있으나 일반적으로 오차항의 모분산인 $\sigma^2$값이 알려지지 않아 검증을 할 수 없습니다. 따러서 $\sigma^2$값을 관측된 표본데이터로부터 구한 표본분산의 계산값을 이용하여 추정해야 합니다. 추정량을 표준화하면 다음과 같습니다.
$\dfrac{(\hat{\beta_1}-\beta_1)}{\sigma_{\beta_1}}\sim N(0,1)$
$\dfrac{(\hat{\beta_0}-\beta_0)}{\sigma_{\beta_0}}\sim N(0,1)$
$\sigma_{Res}^2$과 $\sigma_{\beta_0}^2$, $\sigma_{\beta_1}^2$의 추정량을 구하면, 표본데이터와 LSE인 $\hat{\beta}_1$와 $\hat{\beta}_0$을 이용하여 표본의 잔차인 $e_i$를 도출할 수 있으므로 이를 이용하여 잔차의 모분산($\sigma_{Res}^2$)의 추정량인 잔차의 표본분산($S_{Res}^2$)을 구할 수 있습니다. $(n-2)$로 나누는 이유는 $n$개의 표본데이터로부터 2개의 회귀계수인 $\beta_1$와 $\beta_0$를 추정하는데 사용된 자유도의 감소를 고려한 것입니다.
$S_{Res}^2$ = $\dfrac{1}{n-2}\mathop{\sum}\limits_{i=1}\limits^{n}$ ${e_i}^2$
여기서, $S_{Res}^2$는 잔차의 분산이며 오차항의 모분산의 추정량
$S_{Res}$는 잔차의 표준편차(잔차 표집의 표준편차)이고 회귀직선의 표준오차(standard error of regression)입니다.
$S_{Res}=\mathrm{SE}(\hat{\beta})$
오차항의 분산의 추정량인 잔차의 분산($S_{Res}^2$)을 이용한 모회귀계수인 모기울기와 모절편의 분산의 추정량은 다음식과 같습니다.
$S_{\beta_1}^2=\left(\dfrac{S_{Res}^2}{n}\right)\dfrac{1}{\sum\limits_{i=1}^{n}(X_i-\bar{X})^2}$
$S_{\beta_0}^2=\left(\dfrac{S_{Res}^2}{n}\right)\dfrac{\sum\limits_{i=1}^{n}X_i^2}{\sum\limits_{i=1}^{n}(X_i-\bar{X})^2}$
최소제곱추정량(Least Square Estimator, LSE)의 확률분포에서 $(n-2)$의 자유도를 갖는 $t$분포는 다음식으로 표현합니다.
$\dfrac{(\hat{\beta_1}-\beta_1)}{S_{\beta_1}}\sim t_{n-2}$
$\dfrac{(\hat{\beta_0}-\beta_0)}{S_{\beta_0}}\sim t_{n-2}$
최소제곱법(Ordinary Least Squares, OLS)으로 최선의 표본의 회귀직선 구하기는 잔차제곱합이 최소일 때의 회귀직선의 회귀계수를 구하는 것입니다.
회귀직선을 나타내는 모수(parameter)로써 회귀계수(coefficient of regression)는 모절편($\beta_0$)과 모기울기($\beta_1$)입니다. 회귀계수의 가장 적합한 추정량(estimator: 변수에 모자($\hat{}$, hat)를 씌움)을 구하는 것은 결국 최선의 표본회귀직선을 도출하는 것입니다. 적합도가 가장 큰 표본회귀직선을 구하는 방법 중에서 가장 많이 사용하는 방법은 잔차($e_i=Y_{i}-\hat{Y_i}$)의 제곱의 합이 가장 작은 회귀직선을 구하는 것입니다. 이 방법을 최소제곱법이라고 합니다.
$min\left[\sum\limits_{i=1}^{n}e_i^2\right]=min\left[\sum\limits_{i=1}^{n}(Y_i-\hat{\beta}_0-\hat{\beta}_1{X_i})^2\right]$
표본절편 $(\hat{\beta_0})$과 표본기울기$(\hat{\beta_1})$로 잔차제곱합인 $\left(\sum\limits_{i=1}^{n}e_i^2\right)$을 1차 편미분한 값이 $0$이 될 때 잔차제곱합인 $\left(\sum\limits_{i=1}^{n}e_i^2\right)$은 최소가 됩니다.
$\dfrac{\partial\left(\sum\limits_{i=1}^{n}{e_i}^2\right)}{\partial{\hat{\beta}_0}}=-2\sum\limits_{i=0}^{n}(Y_i+\hat{\beta_0}+\hat{\beta_1}X_i)=0$
$\dfrac{\partial\left(\sum\limits_{i=1}^{n}{e_i}^2\right)}{\partial{\hat{\beta}_1}}=2\sum\limits_{i=0}^{n}\left((Y_i-\hat{\beta_0}-\hat{\beta_1}X_i)X_i\right)=0$
윗식을 다시 표본절편$(\hat{\beta}_0)$ 과 표본기울기$(\hat{\beta}_1)$에 대하여 정리하면 다음식과 같습니다.
표본기울기$(\hat{\beta}_1)$
$\hat{\beta_1}=\dfrac{\sum\limits_{i=1}\limits^{n}(X_i{-}\bar{X})(Y_i{-}\bar{Y})}{\sum\limits_{i=1}\limits^{n}(X_i{-}\bar{X})^2}=\dfrac{(n-1)S_{XY}}{(n-1)S_X^2}=\dfrac{S_{XY}}{S_X^2}$
여기서, $\bar X$는 $X$의 표본평균 : $\bar{X}=\dfrac{1}{n}\sum\limits_{i=1}^{n}{X}_i$
$\bar{Y}$는 $Y$의 표본평균 : $\bar{Y}=\dfrac{1}{n}\sum\limits_{i=1}^{n}{Y}_i$
$S_{XY}$는 $X$와 $Y$의 표본공분산 : $S_{XY}=\dfrac{\sum\limits_{i=1}^{n}(X_i-\bar{X})(Y_i-\bar{Y})}{n-1}$
$S_X^2$는 $X$의 표본분산 : $S_X^2=\dfrac{\sum\limits_{i=1}^{n}(X_i-\bar{X})^2}{n-1}$
$n$은 표본크기
표본절편$(\hat{\beta}_0)$
$$\hat{\beta_0}=\bar{Y}-\hat{\beta_1}\bar{X}$$
여기서, $\hat{\beta_1}$는 회귀직선의 표본기울기
$\bar X$는 $X$의 표본평균 : $\bar{X}=\dfrac{1}{n}\sum\limits_{i=1}^{n}{X}_i$
$\bar{Y}$는 $Y$의 표본평균 : $\bar{Y}=\dfrac{1}{n}\sum\limits_{i=1}^{n}{Y}_i$
$n$은 표본크기
표본절편$(\hat{\beta_0})$과 표본기울기$(\hat{\beta_1})$는 알려지지 않은 모절편$(\beta_0)$과 모기울기$(\beta_1)$의 추정량(estimator)이며, 이들은 확률변수이고 따라서 확률분포를 가집니다. 오차항이 정규분포를 나타내면 이 추정량도 정규분포를 나타냅니다.
Table 1. 최소제곱법의 회귀계수 추정에의 적용
| 용어 | 영문 | 약자 | 역할 | 회귀계수 추정 |
|---|---|---|---|---|
| 최소제곱법 | Ordinary Least Squares | OLS | 방법(Method) | 잔차 제곱합을 최소화하는 회귀계수 추정 방법 $min\left[\sum\limits_{i=1}^{n}e_i^2\right]=min\left[\sum\limits_{i=1}^{n}(Y_i-\hat{\beta}_0-\hat{\beta}_1{X_i})^2\right]$ |
| 최소제곱추정 | Least Squares Estimation | LSE | 과정(Estimation) | OLS 방법을 이용하여 회귀계수를 계산하는 행위 |
| 최소제곱추정량 | Least Squares Estimator | LSE | 결과(Estimator) | OLS 결과로 얻어진 회귀계수 $\hat{\beta_1}=\dfrac{\sum\limits_{i=1}\limits^{n}(X_i{-}\bar{X})(Y_i{-}\bar{Y})}{\sum\limits_{i=1}\limits^{n}(X_i{-}\bar{X})^2}=\dfrac{(n-1)S_{XY}}{(n-1)S_X^2}=\dfrac{S_{XY}}{S_X^2}$ $\hat{\beta_0}=\bar{Y}-\hat{\beta_1}\bar{X}$ |
최소제곱법에 의해 산출된 추정량인 표본절편$(\hat{\beta_0})$과 표본기울기$(\hat{\beta_1})$가 확률변수이기 때문에 통계적 특성(평균, 분산)을 파악할 수 있습니다. 최소제곱법으로 구한 추정량은 기본 가정들이 충족되면 통계적으로 유용한 특성인 불편향성(unbiasedness), 효율성(efficiency), 선형성(linearity) 및 일관성(consistency)을 갖게 됩니다.
1) 비편향성(unbiasedness)
최소제곱법으로 구한 추정량 (least squares estimator: LSE)은 비편향성(unbiasedness)을 갖게 됩니다. 표본의 크기가 크다면 중심극한정리에 의하여 표본절편$(\hat{\beta_0})$과 표본기울기 $(\hat{\beta_1})$의 평균은 모절편$(\beta_0)$과 모기울기$(\beta_1)$의 실제값과 일치하는 특성을 가집니다. 반대로 표본으로부터 구한 표본회귀계수로 모회귀계수의 평균을 추정할 수 있습니다.
$\mathrm{E}[\hat{\beta}_0]=\beta_0$
$\mathrm{E}[\hat{\beta}_1]=\beta_1$
2) 효율성(efficiency)
최소제곱법으로 구한 추정량, LSE(least squares estimator)는 효율성을 갖습니다. 즉, 가능한 모든 비편향 추정량(unbiased estimators)중에서 최소의 분산을 가집니다. 잔차의 분산($\sigma^2$)이 커질수록 LSE의 분산은 커지고 LSE는 덜 정확한 추정치를 나타내게 됩니다. 독립변수($X$)의 값이 넓게 퍼져 있을수록 즉, $\sum\limits_{i=1}^{n}(X_i-\bar{X})^2$이 클수록 LSE 의 분산은 작아지고 독립변수의 변화에 의한 종속변수의 변화를 상대적으로 잘 설명할 수 있습니다. 표본크기($n$)가 증가할수록 $\sum\limits_{i=1}^{n}n(X_i-\bar{X})^2$의 값이 증가하게 되어 LSE 의 분산과 공분산이 작아집니다. 이는 표본크기가 클수록 표본이 모집단에 근접하게 되어 모수에 대한 정보를 더 정확하게 구할 수 있기 때문입니다. 공분산은 독립변수($X$)의 평균($\bar{X}$)과 반대 부호를 가집니다. LSE 는 다음식과 같이 표본분산과 표본공분산을 나타냅니다.
절편 추정량의 분산
\[
\mathrm{Var}[\hat{\beta}_0]
= \mathrm{Var}\left[\bar{Y} – \hat{\beta}_1 \bar{X}\right]
= \mathrm{Var}[\bar{Y}]
+ \bar{X}^2 \cdot \mathrm{Var}[\hat{\beta}_1]
– 2\bar{X} \cdot \mathrm{Cov}[\bar{Y}, \hat{\beta}_1]
\]
그런데 $\bar{Y}$와 $\hat{\beta}_1$은 독립이므로 공분산 항이 0이 됩니다.
\[
\mathrm{Var}[\hat{\beta}_0] = \frac{\sigma^2}{n} + \bar{X}^2 \cdot \mathrm{Var}[\hat{\beta}_1]
= \frac{\sigma^2}{n} + \bar{X}^2 \cdot \left( \frac{\sigma^2}{\sum_{i=1}^n (X_i – \bar{X})^2} \right)
\]
정리하면
\[
\mathrm{Var}[\hat{\beta}_0] = \sigma^2 \left( \frac{1}{n} + \frac{\bar{X}^2}{\sum\limits_{i=1}^n (X_i – \bar{X})^2} \right)
\]
기울기 추정량의 분산
$$\hat{\beta}_1 = \dfrac{\sum (X_i – \bar{X})(Y_i – \bar{Y})}{\sum (X_i – \bar{X})^2}$$
\[
\mathrm{Var}[\hat{\beta}_1] = \frac{\sigma^2}{\sum\limits_{i=1}^n (X_i – \bar{X})^2}
\]
절편과 기울기 추정량의 공분산
\[
\mathrm{Cov}[\hat{\beta}_0, \hat{\beta}_1] = -\bar{X} \cdot \mathrm{Var}[\hat{\beta}_1]
\]
\[
\mathrm{Cov}[\hat{\beta}_0, \hat{\beta}_1] = -\bar{X} \cdot \left( \frac{\sigma^2}{\sum\limits_{i=1}^n (X_i – \bar{X})^2} \right)
\]
3) 선형성(linearity)
아래에 정의된 두개의 LSE 모두 $Y_i$ 의 1차함수관계인 선형추정량(linear estimator)입니다.
$\hat{\beta_1}=\dfrac{\sum\limits_{i=1}^{n}{x_i}{y_i}}{\sum\limits_{i=1}^{n}{x_i}^2}=\sum\limits_{i=1}^{n}{C_i}{y_i}$
여기서, $C_i=\dfrac{\sum\limits_{i=1}^{n}{x_i}}{\sum\limits_{i=1}^{n}{x_i}^2}$
$\hat{\beta_0}=\bar{Y}-\hat{\beta_1}\bar{X}=\bar{Y}-\bar{X}\sum\limits_{i=1}^{n}{C_i}{y_i}$
4) 가우스-마르코프 정리 (Gauss-Markov Theorem)
최소제곱추정량(LSE)은 최선선형불편향추정량(Best Linear Unbiased Estimator: BLUE)입니다. 최소제곱추정량(LSE)은 선형이고 불편향인 추정량들 가운데 최선(best)의 추정량입니다. 최선(best)은 최소의 분산을 갖는 것을 의미합니다. 모회귀계수($\beta_0$, $\beta_1$)의 추정량(estimator)으로서 선형(linear)이고 불편향(unbiased)인 추정량중에서는 최소제곱추정량(LSE)이 분산이 가장 작은 최선의 추정량입니다.
Table 2. 추정량 수식표현
| 추정량 | 수식 표현 |
|---|---|
| $\mathrm{Var}[\hat{\beta}_0]$ | $\sigma^2 \left( \dfrac{1}{n} + \dfrac{\bar{X}^2}{\sum\limits_{i=1}^n (X_i – \bar{X})^2} \right)$ |
| $\mathrm{Var}[\hat{\beta}_1]$ | $\dfrac{\sigma^2}{\sum\limits_{i=1}^n (X_i – \bar{X})^2}$ |
| $\mathrm{Cov}[\hat{\beta}_0, \hat{\beta}_1]$ | $-\dfrac{\sigma^2 \bar{X}}{\sum\limits_{i=1}^n (X_i – \bar{X})^2}$ |
단순선형회귀에서 회귀계수의 추정량은 기울기와 절편의 추정량입니다. 추정량의 표준오차(standard error)인 $SE((\hat{\beta_0}))$와 $SE((\hat{\beta_1}))$는 절편과 기울기의 추정값에 대한 신뢰도를 평가하는 데 사용되는 추정된 회귀계수가 실제 모수값을 얼마나 정확하게 추정하는지에 대한 불확실성을 나타내는 값입니다. 잔차(residual)의 표준편차인 $\hat{\sigma}$는 모델의 적합성을 평가하는 지표로 활용됩니다.
오차의 표준편차 추정값은 단순선형회귀식의 오차항의 표준편차에 대한 추정치 (Residual Standard Error, RSE 또는 Root Mean Square Error, RMSE)입니다.
\[
\hat{\sigma} = \sqrt{ \dfrac{\sum\limits_{i=1}^{n} (y_i – \hat{y_i})^2}{n – 2} }= \sqrt{ \dfrac{\sum\limits_{i=1}^{n} (y_i – \hat{\beta_0} – \hat{\beta_1} x_i)^2}{n – 2} }
\]
여기서, $\hat{\sigma}$는 표본 데이터로 추정한 오차항의 표준편차
$\bar{x}$은 독립변수 $X$의 표본평균
$n$은 표본 크기
$x_i$와 $ y_i$는 독립변수와 종속변수의 관측값
$\hat{\beta_0}$와 $\hat{\beta_1}$는 절편과 기울기 추정값
\[
SE(\hat{\beta_0}) = \sigma \sqrt{ \frac{1}{n} + \frac{\bar{x}^2}{\sum\limits_{i=1}^{n} (x_i – \bar{x})^2} }
\]
\[
\widehat{SE(\hat{\beta_0})} = \hat{\sigma} \sqrt{ \frac{1}{n} + \frac{\bar{x}^2}{\sum\limits_{i=1}^{n} (x_i – \bar{x})^2} }
\]
여기서, $\sigma$는 모집단 오차항의 표준편차 (일반적으로 알려지지 않음)
$\hat{\sigma}$는 표본 데이터로 추정한 오차항의 표준편차
$\bar{x}$은 독립변수 $X$의 표본평균
$n$은 표본 크기
$x_i$와 $ y_i$는 독립변수와 종속변수의 관측값
$\hat{\beta_0}$와 $\hat{\beta_1}$는 절편과 기울기 추정값
독립변수 $X$의 값이 많이 분산될수록, 즉 $\sum(x_i-\bar x)^2$가 클수록 기울기의 표준오차는 작아집니다. 다음식은 기울기 추정값 $\hat{\beta_1}$의 표준오차를 계산하는 공식입니다.
\[
SE(\hat{\beta_0})= \sigma \sqrt{ \dfrac{1}{\sum\limits_{i=1}^{n} (x_i – \bar{x})^2} }
\]
\[
\widehat{SE(\hat{\beta_1})} = \hat{\sigma} \sqrt{ \dfrac{1}{\sum\limits_{i=1}^{n} (x_i – \bar{x})^2} }
\]
여기서, $\sigma$는 모집단 오차항의 표준편차 (일반적으로 알려지지 않음)
$\hat{\sigma}$는 표본 데이터로 추정한 오차항의 표준편차
$\bar{x}$은 독립변수 $X$의 표본평균
$n$은 표본 크기
$x_i$와 $ y_i$는 독립변수와 종속변수의 관측값
$(\hat{\beta_0})$와 $(\hat{\beta_1})$는 절편과 기울기 추정값
Table 2. RSME(Root Mean Square Error) 비교
| 수식 유형 | 수식 | 사용 용도 | 자유도 고려 여부 |
|---|---|---|---|
| 일반 RMSE | \(\text{RMSE} = \sqrt{ \dfrac{1}{n} \sum\limits_{i=1}^{n} (y_i – \hat{y}_i)^2 }\) | 모델의 예측 정확도 평가 | 고려하지 않음 |
회귀분석 RMSE (RSE, Residual Standard Error) | \(\text{RSE} = \sqrt{ \dfrac{1}{n – 2} \sum\limits_{i=1}^{n} (y_i – \hat{y}_i)^2 }\) | 회귀분석의 잔차 평가 | 고려함 (자유도 \( n-2 \)) |
개별값을 추정하는 것이 평균값을 추정하는 것보다 더 어렵습니다. 개별값을 추정할때의 표준오차가 평균값을 추정할 때의 표준오차보다 더 크기 때문에 개별값 추정은 평균값 추정보다 더 많은 불확실성을 포함하게 됩니다.
특정값 $x_0$에서의 실제값 $y_0$를 추정한 값을 $\hat{y}_0$로 하면, 추정값의 표준오차는 다음식과 같이 계산됩니다. 식의 마지막 항인 1은 추정값과 관측값 간의 차이를 나타내는 오차항(잔차)으로부터 유도된 수입니다.
\[
\widehat{SE(\hat{y}_0 – y_0)} = \hat{\sigma} \sqrt{ \frac{1}{n} + \dfrac{(x_0 – \bar{x})^2}{\sum\limits_{i=1}^{n} (x_i – \bar{x})^2}+1}
\]
여기서, $\hat\sigma$는 잔차의 표준편차 추정값 (RSE)
$n$은 표본크기
$x_0$는 특정 독립변수값
$\bar x$는 독립변수의 표본평균
여러 개의 $x_i$ 에 대한 평균을 추정하는 경우, 표준오차는 추정된 평균값의 불확실성을 반영합니다. 이때 계산되는 표준오차는 특값 추정의 표준오차와는 달리, 잔차(오차항)에서 기인한 수인 1이 포함되지 않습니다.
\[
\widehat{SE(\hat{y}_0 – y_0)} = \hat{\sigma} \sqrt{ \frac{1}{n} + \dfrac{(x_0 – \bar{x})^2}{\sum\limits_{i=1}^{n} (x_i – \bar{x})^2}}
\]
특정값 추정의 표준오차가 더 큽니다. 이유는 특정값을 추정하는 경우에는 추정값뿐만 아니라 실제 관측값 자체의 오차도 포함되기 때문입니다. 다른 관점으로 평균값 추정의 표준오차는 더 작습니다. 이유는 평균을 구하는 과정에서 오차가 상쇄되기 때문입니다. 정리하면 관측값의 평균을 추정할 때는 특정값을 추정할 때보다 불확실성이 줄어듭니다.
\[
SE(\hat{y}_0 – y_0) > SE(\hat{E}[y_0] – \bar{y})
\]
여기서, $\hat{\sigma}$는 표본 데이터로 추정한 오차항의 표준편차
$\bar{x}$은 독립변수 $X$의 표본평균
$n$은 표본 크기
$x_i$와 $ y_i$는 독립변수와 종속변수의 관측값
$\hat{\beta_0}$와 $\hat{\beta_1}$는 절편과 기울기 추정값
특정값의 95% 신뢰수준에서의 구간추정
\[
\hat{y}_0 \pm 2 SE(y_0 – \hat{y}_0) = \hat{\beta_0} + \hat{\beta_1} x_0 \pm 2 \hat{\sigma} \sqrt{ \frac{1}{n} + \frac{(x_0 – \bar{x})^2}{\sum\limits_{i=1}^{n} (1+ x_i – \bar{x})^2}}
\]
여기서, $\hat{y_0}$는 점추정된 값
$x_0$는 예측하고자 하는 독립변수값
$\hat{\beta_0}$는 회귀절편 추정값
$(\hat{\beta_1})$는 회귀기울기 추정값
$\hat \sigma$는 잔차의 표준편차 (RSE)
$n$은 표본크기
$\bar x$는 독립변수 $x_i$의 표본평균
평균값의 95% 신뢰수준에서의 구간추정
\[
\hat{y}_0 \pm 2 SE(E(y_0) – \hat{y}_0) = (\hat{\beta_0}) + (\hat{\beta_1}) x_0 \pm 2 \hat{\sigma} \sqrt{ \frac{1}{n} + \frac{(x_0 – \bar{x})^2}{\sum\limits_{i=1}^{n} (x_i – \bar{x})^2} }
\]
Table 3. 개별값과 평균값의 구간추정 비교
| 구간추정 대상 | 구간추정 수식 | 특징 |
|---|---|---|
| 특정값 | \( \hat{y}_0 \pm 2 \hat{\sigma} \sqrt{ \frac{1}{n} + \dfrac{(x_0 – \bar{x})^2}{\sum\limits_{i=1}^{n} (x_i – \bar{x})^2}+1} \) | 예측의 불확실성이 큼 (+1 추가 항) |
| 평균값 | \( \hat{y}_0 \pm 2 \hat{\sigma} \sqrt{ \frac{1}{n} + \dfrac{(x_0 – \bar{x})^2}{\sum\limits_{i=1}^{n} (x_i – \bar{x})^2} } \) | 예측의 불확실성이 작음 (+1 추가 항 없음) |
Table 3. 추정량 표현
| 분산 추정량 표현 | 의미 |
|---|---|
| $\hat{\beta}_0$ | $x = 0$에서의 예측값 |
| $\hat{y}_{\bar{X}}$ | $x = \bar{X}$일 때의 예측값 → 평균 입력값에서의 예측 결과 |
| $\hat{y}_{x_0}$ | $x = x_0$일 때의 예측값 → 특정 입력값에서의 예측 결과 |
개별값을 추정하는 것이 평균값을 추정하는 것보다 더 어렵습니다. 개별값을 추정할때의 표준오차가 평균값을 추정할 때의 표준오차보다 더 크기 때문에 개별값 추정은 평균값 추정보다 더 많은 불확실성을 포함하게 됩니다.
단순회귀분석에서 기울기 가설검정에서의 귀무가설은 “기울기가 0이다” 입니다. 이는 독립변수 $x$가 종속변수 $y$를 설명을 못한다는 의미입니다. 귀무가설에 따른 대립가설은 3가지가 있습니다.
귀무가설 $H_0: \beta_1=0$
양측검정 대립가설 $H_1: \beta_1 \ne 0$
우측 단측검정 대립가설 $H_1: \beta_1 > 0$
좌측 단측검정 대립가설 $H_1: \beta_1 < 0$
t검정통계량
$$t_{test} = \dfrac{\hat{\beta_1} – 0}{\widehat{\mathrm{SE}}(\hat{\beta}_1)}$$
여기서, $\widehat{\mathrm{SE}}(\hat{\beta}_1)$는 기울기의 표준오차 추정량:
$$\widehat{\mathrm{SE}}(\hat{\beta}_1) = \hat{\sigma} \sqrt{ \frac{1}{\sum\limits_{i=1}^{n}(x_i – \bar{x})^2} }$$
구간추정
기울기에 대한 신뢰수준 95%에서 신뢰구간에 검정통계량 $\beta_1$가 들어가는 지를 확인하여 포함되지 않으면 귀무가설을 기각됩니다.
$$\beta_1 \notin \left( \hat{\beta}_1 \pm t_{\alpha/2,\, n – 2} \cdot \widehat{\mathrm{SE}}(\hat{\beta}_1) \right) \Rightarrow \text{귀무가설 기각}$$
가설검정
유의수준 $\alpha$에서, 자유도 $n – 2$를 갖는 t-분포의 임계값 $t_{\alpha/2,\, n-2}$와 비교합니다.
$$|t| \ge t_{\alpha/2,\, n-2} \Rightarrow \text{귀무가설 기각}$$
즉, $\beta_1$은 유의수준 $\alpha$에서 통계적으로 유의하다는 결론을 내릴 수 있습니다.
가설
귀무가설 $H_0: \beta_0 = 0$
대립가설 $H_1: \beta_0 \neq 0$
t검정통계량
$$t_{test}=\dfrac{\hat{\beta}_0 – \beta_0}{\widehat{\mathrm{SE}}(\hat{\beta}_0)}$$
여기서, $\hat{\beta}_0$은 표본에서 추정된 절편
$\beta_0$은 가설에서 주장하는 절편 (예: 0)
$\widehat{\mathrm{SE}}(\hat{\beta}_0)$는 절편의 표준오차 추정량:
$$\widehat{\mathrm{SE}}(\hat{\beta}_0) = \hat{\sigma} \sqrt{ \frac{1}{n} + \frac{\bar{x}^2}{\sum\limits_{i=1}^{n}(x_i – \bar{x})^2} }$$
가설검정
유의수준 $\alpha$에서, 자유도 $n – 2$를 갖는 t-분포의 임계값 $t_{\alpha/2,\, n-2}$와 검정통계량을 비교합니다.
$$|t| \ge t_{\alpha/2,\, n-2} \Rightarrow \text{귀무가설 기각}$$
즉, $\beta_0$는 유의수준 $\alpha$에서 통계적으로 유의하다는 결론을 내릴 수 있습니다.
오차항 $\epsilon$은 독립이고 정규분포를 따른다고 가정하면 종속변수는 다음과 같습니다.
$$Y_i=\beta_0 + \beta_1X_i + \epsilon_i \sim N(\beta_0 + \beta_1X_i , \, \sigma_{Res}^2)$$
$\beta_1$의 최소제곱추정량(LSE=$\hat{\beta}_1$)은 다음과 같습니다.
$$\eqalign{\hat{\beta}_1&=\dfrac{\sum\limits_{i=1}^{n}(X_i-\bar{X})(Y_i-\bar{Y})}{\sum\limits_{i=1}^{n}(X_i-\bar{X})^2}\cr&=\dfrac{\sum\limits_{i=1}^{n}(X_i-\bar{X})(Y_i-\bar{Y})}{SS_{X}}\cr&=\dfrac{\sum\limits_{i=1}^{n}(X_i-\bar{X})Y_i-\sum\limits_{i=1}^{n}(X_i-\bar{X})\bar{Y}}{SS_{X}}\cr&=\dfrac{\sum\limits_{i=1}^{n}(X_i-\bar{X})Y_i}{SS_{X}}\cr&=\sum\limits_{i=1}^{n}\left(\dfrac{X_i-\bar{X}}{SS_{X}}\right)Y_i}$$
따라서, 표본회귀직선기울기의 기대값은
$$\eqalign{\mathrm{E}[\hat{\beta}_1]&=\mathrm{E}\left\lbrack\sum\limits_{i=1}^{n}\left(\dfrac{X_i-\bar{X}}{SS_{X}}\right) Y_i\right\rbrack\cr&=\sum\limits_{i=1}^{n}\left(\dfrac{X_i-\bar{X}}{SS_{X}}\right)\mathrm{E}[Y_i]\cr&=\dfrac{\sum\limits_{i=1}^{n}(X_i-\bar{X})(\beta_0+\beta_1 X_1)}{SS_{X}}\cr&=\dfrac{(\beta_0 + \beta_1 \bar{X})\sum\limits_{i=1}^{n}(X_i-\bar{X})+\beta_1 SS_{X}}{SS_{X}}\cr&=\beta_1}$$
그리고, 표본회귀직선기울기의 분산은
$$\eqalign{\mathrm{Var}[\hat{\beta}_1]&=\mathrm{Var}\left\lbrack\sum\limits_{i=1}^{n}\left(\dfrac{X_i-\bar{X}}{SS_{X}}\right)Y_i\right\rbrack\cr&=\sum\limits_{i=1}^{n}\left(\dfrac{X_i-\bar{X}}{SS_{X}}\right)^2 \mathrm{Var}[Y_i]\cr&=\sum\limits_{i=1}^{n}\dfrac{(X_i-\bar{X})^2}{(SS_{X})^2}\sigma_{Res}^2\cr&=\dfrac{\sigma^2}{(SS_{X})^2}\sum\limits_{i=1}^{n}(X_i-\bar{X})^2\cr&=\dfrac{\sigma_{Res}^2}{SS_{X}}}$$
표본회귀직선기울기의 분포는 다음과 같습니다.
$$\hat{\beta}_1\sim N\left(\beta_1,\ \dfrac{\sigma_{Res}^2}{SS_{X}}\right)$$
$\hat{\beta}_1$의 분포를 표준화하면 다음과 같습니다.
$$\dfrac{\hat{\beta}_1-\beta_1}{\dfrac{\sigma_{Res}}{\sqrt{SS_{X}}}}\sim N(0,\ 1)$$
$$\eqalign{P\left(\left|\dfrac{\hat{\beta}_1-\beta_1}{\dfrac{\sigma_{Res}}{\sqrt{SS_{X}}}}\right|\lt z_{\frac{\alpha}{2}}\right)&=P\left(\left|\hat{\beta}_1-\beta_1 \right|\lt z_{\frac{\alpha}{2}}\dfrac{\sigma_{Res}}{\sqrt{SS_{X}}}\right)\cr&=1-\alpha}$$
오차항의 분산 $\sigma_{Res}^2$을 알고 있는 경우 모기울기($\beta_1$)에 대한 $100(1-\alpha)$% 신뢰구간은 다음과 같습니다.
$$\left(\hat{\beta}_1-z_{\frac{\alpha}{2}}\dfrac{\sigma_{Res}}{\sqrt{SS_{X}}},\ \hat{\beta}_1+z_{\frac{\alpha}{2}}\dfrac{\sigma_{Res}}{\sqrt{SS_{X}}}\right)$$
$\hat{\beta_0}$은 $\beta_0$의 최소제곱불편추정량이며 기대값은 다음과 같이 $\beta_0$입니다.
$$\eqalign{\mathrm{E}[\hat{\beta}_0]&=\mathrm{E}[\bar{Y}-\hat{\beta}_1 \bar{X}]\cr&=(\beta_0+\beta_1\bar{X})-\hat{\beta}_1\bar{X}\cr&=\beta_0}$$
$\hat{\beta_0}$의 분산은 다음과 같이 구할 수 있습니다.
$$\eqalign{\mathrm{Var}[\hat{\beta}_0]&=\mathrm{Var}[\bar{Y}-\hat{\beta}_1\bar{X}]\cr&=\mathrm{Var}[\bar{Y}]+\bar{X}^2 \mathrm{Var}[\hat{\beta}_1]-2\bar{X}\ \mathrm{Cov}[\bar{Y},\ \hat{\beta}_1]\cr&=\dfrac{\sigma_{Res}^2}{n}+\dfrac{\bar{X}^2\sigma_{Res}^2}{SS_{X}}-2\bar{X}\ \mathrm{Cov}[\bar{Y},\ \hat{\beta}_1]\cr&=\left(\dfrac{1}{n}+\dfrac{\bar{X}^2}{SS_{X}}\right)\sigma_{Res}^2-2\bar{X}\ \mathrm{Cov}[\bar{Y},\ \hat{\beta}_1]}$$
여기서, $Y_i$는 독립 $\mathrm{Cov}(\bar Y, \hat {\beta_1})=0$ 이고 $\sum\limits_{i=1}^{n}(X_i – \bar X)=0$
$$\eqalign{\mathrm{Cov}(\bar{Y},\ \hat{\beta}_1)&=\mathrm{Cov}\left(\sum\limits_{i=1}^{n}\dfrac{1}{n}Y_i,\ \sum\limits_{i=1}^{n}\dfrac{X_i-\bar{X}}{SS_{X}}Y_i\right)\cr&=\sum\limits_{i=1}^{n}\left(\dfrac{1}{n}\cdot\dfrac{X_i-\bar{X}}{SS_{X}}\right)\ \mathrm{Var}(Y_i)+\sum\limits_{i\ne j}\left(\dfrac{1}{n}\cdot\dfrac{X_i-\bar{X}}{SS_{X}}\right)\ \mathrm{Cov}(Y_i,\ Y_j)\cr&=\sum\limits_{i=1}^{n}\left(\dfrac{1}{n}\cdot\dfrac{X_i-\bar{X}}{SS_{X}}\right)\sigma_{Res}^2\cr&=\dfrac{1}{n}\cdot\dfrac{\sigma^2}{SS_{X}}\sum\limits_{i=1}^{n}(X_i-\bar{X})\cr&=0}$$
윗식을 정리하면, $\hat{\beta}_0$의 분산은 다음과 같습니다.
$$\mathrm{Var}[Y_i]=\left(\dfrac{1}{n}+\dfrac{\bar{X}^2}{SS_{X}}\right)\sigma_{Res}^2$$
$\bar{Y}$와 $\hat{\beta}_1$이 정규분포를 이루므로 ($\hat{\beta}_0=\bar{Y}-\hat{\beta}_1\bar{x}$)도 정규분포를 이룹니다. 따라서 모절편($\beta_0$)의 최소제곱불편추정량인 $\hat{\beta}_0$은 다음과 같이 정규분포인 확률분포를 나타냅니다,
$$\hat{\beta}_0\sim N\left(\beta_0,\ \left(\dfrac{1}{n}+\dfrac{\bar{X}^2}{SS_{X}}\right)\sigma_{Res}^2\right)$$
$\hat{\beta}_0$의 확률분포를 표준화하면 다음과 같습니다.
$$\dfrac{\hat{\beta}_0-\beta_0}{\sigma_{Res}\sqrt{\dfrac{1}{n}+\dfrac{\bar{X}^2}{SS_{X}}}}\sim N(0,\ 1)$$
유의수준$(\alpha)$이 나타내는 신뢰구간 확률은 다음과 같습니다.
$$\eqalign{P\left(\left|\dfrac{\hat{\beta}_0-\beta_0}{\sigma_{Res}\sqrt{\dfrac{1}{n}+\dfrac{\bar{X}^2}{SS_{X}}}}\right|\lt z_{\frac{\alpha}{2}}\right)&=P\left(\hat{\beta}_0-z_{\frac{\alpha}{2}}\sigma_{Res}\sqrt{\dfrac{1}{n}+\dfrac{\bar{X}^2}{SS_{X}}}\lt\beta_0\lt\hat{\beta}_0+z_{\frac{\alpha}{2}}\sigma_{Res}\sqrt{\dfrac{1}{n}+\dfrac{\bar{X}^2}{SS_{X}}}\right)\cr&=1-\alpha}$$
모절편$(\beta_0)$의 $100(1-\alpha)\%$ 신뢰구간은 다음과 같습니다.
$$\left(\hat{\beta}_0-z_{\frac{\alpha}{2}}\sigma_{Res}\sqrt{\dfrac{1}{n}+\dfrac{\bar{X}^2}{SS_{X}}},\ \hat{\beta}_0+z_{\frac{\alpha}{2}}\sigma_{Res}\sqrt{\dfrac{1}{n}+\dfrac{\bar{X}^2}{SS_{X}}}\right)$$
두 확률변수 $X$와 $Y$의 관계를 다음식으로 나타낼 수 있습니다.
$$Y=\beta_0+\beta_1 X^{\ast}+\varepsilon $$
${\rm E}(\varepsilon)=0$ 이면 조건부 기대값인 ${\rm E}\left[Y|X=X^{\ast}\right]$은 다음과 같습니다.
$$\eqalign{\mathrm{E}\left[Y|X=X^{\ast}\right]&=\mathrm{E}\left[\beta_0+\beta_1 X|X=X^{\ast}\right]\cr&=\beta_0+\beta_1 X^{\ast}}$$
$X=X^\ast$일 때의 $Y$의 조건부 기대값은 독립변수인 $X^\ast$에 대응하는 종속변수($Y|X=X^{\ast}$)의 평균값을 의미합니다. $\hat{\beta}_0$와 $\hat{\beta}_1$이 각각 $\beta_0$와 $\beta_1$의 최소제곱불편추정량이므로 $(\hat{Y}=\hat{\beta}_0+\hat{\beta}_1 X^{\ast})$는 ${\rm E}\left[Y|X=X^\ast\right]=\hat{\beta}_0+\hat{\beta}_1 X^{\ast}$의 불편추정량입니다.
$\hat{Y}$의 기대값은 다음과 같습니다
$$\eqalign{\mathrm{E}[\hat{Y}]&=\mathrm{E}[\hat{\beta}_0+\hat{\beta}_1 X^{\ast}]\cr&=\beta_0+\beta_1 X^{\ast}}$$
$\hat{Y}$의 분산은 다음과 같습니다
$$\eqalign{\mathrm{Var}[\hat{Y}]&=\mathrm{Var}[\hat{\beta}_0+\hat{\beta}_1 X^{\ast}]\cr&=\mathrm{Var}[\hat{\beta}_0]+(X^{\ast})^2 \mathrm{Var}[\hat{\beta}_1]+2X^{\ast} \mathrm{Cov}[\hat{\beta}_0,\ \hat{\beta}_1]\cr&=\mathrm{Var}[\hat{\beta}_0]+(X^{\ast})^2 \mathrm{Var}[\hat{\beta}_1]+2X^{\ast} \mathrm{Cov}[\bar{Y}-\hat{\beta}_1 \bar{X},\ \hat{\beta}_1]\cr&=\mathrm{Var}[\hat{\beta}_0]+(X^{\ast})^2 \mathrm{Var}[\hat{\beta}_1]-2X^{\ast}\ \bar{X} \mathrm{Var}[\hat{\beta}_1]\cr&=\left(\dfrac{1}{n}+\dfrac{(X^{\ast}-\bar{X})^2}{SS_{X}}\right)\sigma_{Res}^2}$$
$\hat{\beta}_0$과 $\hat{\beta}_1$이 각각 정규분포를 따르므로 $(\hat{Y}=\hat{\beta}_0+\hat{\beta}_1 X^{\ast})$도 다음식과 같이 정규분포를 따릅니다.
$$\hat{\beta}_0+\hat{\beta}_1 X^{\ast}\sim N\left(\beta_0+\beta_1 X^{\ast},\ \left(\dfrac{1}{n}+\dfrac{(X^{\ast}-\bar{X})^2}{SS_{X}}\right)\sigma_{Res}^2\right)$$
$X=X^{\ast}$이고 $\sigma_{Res}^2$이 알려진 경우에 모회귀직선의 $(\beta_0+\beta_1 X^{\ast})$의 $(\hat{\beta}_0+\hat{\beta}_1 X^{\ast})$에 대한 $100(1-\alpha)\%$ 신뢰구간은 다음과 같습니다.
$$\left((\hat{\beta}_0+\hat{\beta}_1 X^{\ast})-z_{\frac{\alpha}{2}}\sigma_{Res}\sqrt{\dfrac{1}{n}+\dfrac{(X^{\ast}-\bar{X})^2}{SS_{X}}},\ (\hat{\beta}_0+\hat{\beta}_1 X^{\ast})+z_{\frac{\alpha}{2}}\sigma_{Res}\sqrt{\dfrac{1}{n}+\dfrac{(X^{\ast}-\bar{X})^2}{SS_{X}}}\right)$$
그러나 일반적으로 오차분산$(\sigma_{Res}^2)$을 알 수 없으므로 모절편$(\beta_0)$과 모기울기$(\beta_1)$에 대한 추론에서 정규분포를 이용할 수 없습니다. 따라서 모절편$(\beta_0)$과 모기울기$(\beta_1)$에 대한 추론을 위해 모표준편차$(\sigma_{Res})$를 표본표준편차$(\hat{\sigma_{Res}}=S_{Res})$로 대치하면 표본절편$(\hat{\beta}_0)$과 표본기울기$(\hat{\beta}_1)$에 대해 다음식과 같은 $t$분포를 얻을 수 있습니다.
$$\dfrac{\hat{\beta}_1 -\beta_1}{\dfrac{S_{Res}}{\sqrt{SS_{X}}}}\sim t(n-2)$$
$$\dfrac{\hat{\beta}_0 -\beta_0}{S_{Res}\sqrt{\dfrac{1}{n}+\dfrac{\bar{X}^2}{SS_{X}}}}\sim t(n-2)$$
모절편$(\beta_0)$의 $100(1-\alpha)\%$ 신뢰구간은 다음과 같습니다.
$$\left(\hat{\beta}_0-t_{n-2 \, ; \, \frac{\alpha}{2}}S_{Res}\sqrt{\dfrac{1}{n}+\dfrac{\bar{X}^2}{SS_{X}}},\ \hat{\beta}_0+t_{n-2 \, ; \, \frac{\alpha}{2}}S_{Res}\sqrt{\dfrac{1}{n}+\dfrac{\bar{X}^2}{SS_{X}}}\right)$$
모기울기$(\beta_1)$의 $100(1-\alpha)\%$ 신뢰구간은 다음과 같습니다.
$$\left(\hat{\beta}_1-t_{n-2 \, ; \, \frac{\alpha}{2}}\dfrac{S_{Res}}{\sqrt{SS_{X}}},\ \hat{\beta}_1+t_{n-2 \, ; \, \frac{\alpha}{2}}\dfrac{S_{Res}}{\sqrt{SS_{X}}}\right)$$
독립변수가 $X$가 $X^{\ast}$로 실현되었을 때 추정회귀선의 종속변수인 ($Y=\hat{\beta}_0+{\hat{\beta}_1}(X|X=X^{\ast}$))는 다음과 같이 자유도가 $(n-2)$인 $t$분포를 따릅니다.
$$\dfrac{(\hat{\beta}_0+\hat{\beta}_1 X^{\ast})-(\beta_0+\beta_1 X^{\ast})}{S_{Res}\sqrt{\dfrac{1}{n}+\dfrac{(X^{\ast}-\bar{X})^2}{SS_{X}}}}\sim t(n-2)$$
따라서, 독립변수가 $X=X^{\ast}$인 조건으로 실현되었을 때 ($Y=\beta_0+{\beta_1}(X|X=X^{\ast})$)의 $100(1-\alpha)\%$ 신뢰구간은 다음과 같습니다.
$$\left((\hat{\beta}_0+\hat{\beta}_1 X^{\ast})-t_{n-2 \, ; \, \frac{\alpha}{2}}S_{Res}\sqrt{\dfrac{1}{n}+\dfrac{(X^{\ast}-\bar{X})^2}{SS_{X}}},\ (\hat{\beta}_0+\hat{\beta}_1 X^{\ast})+t_{n-2 \, ; \, \frac{\alpha}{2}}S_{Res}\sqrt{\dfrac{1}{n}+\dfrac{(X^{\ast}-\bar{X})^2}{SS_{X}}} \right)$$
확률이론 및 통계에서 공분산(covariance)은 두 확률변수의 연결된 가변성(the joint variability)을 측정한 것입니다. 한 변수의 큰 값이 다른 변수의 큰 값과 주로 일치하고 작은 값에서도 동일한 경향이 유지되는 경우 (즉, 두 변수가 유사한 행동을 보이는 경향이 있는 경우), 공분산은 양수입니다. 반대의 경우에, 하나의 변수의 큰 값이 다른 변수의 더 작은 값에 주로 대응할 때 (즉, 변수가 반대의 행동을 나타내는 경향이있는 경우), 공분산은 음의 값을 가집니다. 따라서 공분산의 부호는 변수간의 선형 관계의 경향을 보여줍니다.
공분산의 크기는 정규화되지 않았기 때문에 해석하기가 쉽지 않으므로 변수의 크기에 따라 달라집니다. 그러나 공분산을 정규화한 상관계수는 크기에 따라 선형 상관관계의 강도를 보여줍니다. 아래의 둘은 반드시 구분되어야 합니다.
(1) 두 확률변수의 모공분산(the covariance of two random variables). 여기서 모공분산은 모집단 매개변수(population parameter)이고 모집단 매개변수는 연관 확률분포(joint probability distribution)의 특성으로 볼 수 있습니다.
(2) 표본공분산(the sample covariance). 여기서 표본공분산은 표본을 표현할 뿐만 아니라 모집단 매개변수의 추정값으로 제공됩니다.
출처
통계에서 상관(dependence or association)은 두 확률변수(random variables or bivariate data)의 인과에는 무관한 단지 통계적 관계일 뿐입니다. 가장 넓은 의미에서 상관관계(correlation)는 통계적 연관성이지만 일반적으로는 한 쌍의 두 확률변수가 선형적으로 관련되는 정도를 나타냅니다. 상관에 부가되는 인과의 예는 부모와 자녀의 육체적인 체격 사이의 상관관계와 한정적으로 공급되는 제품에 대한 수요와 그 가격 간의 상관관계가 있습니다. 상관관계는 실제로 활용될 수 있는 예측가능한 관계(causal relationship)를 나타내기 때문에 유용합니다. 예를 들어, 발전소는 전기수요와 날씨 간의 상관관계를 기반으로 온화한 날에 적은 전력을 생산할 수 있습니다. 왜냐하면 극단적인 날씨에 사람들이 난방이나 냉방에 더 많은 전기를 사용하기 때문입니다.
일반적으로, 상관관계의 존재는 인과 관계의 존재를 추론하기에 충분하지 않습니다 (즉, 상관관계는 인과 관계를 의미하지 않습니다).
공식적으로, 확률변수가 확률적 독립(probabilistic independence)의 수학적 성질을 만족시키지 않는다면 종속변수입니다.
비공식적인 의미에서 상관관계는 종속성과 동의어입니다. 그러나 기술적인 의미에서 사용될 때, 상관은 평균값들 사이의 관계 중 어떤 몇 가지 특정 유형을 의미합니다. 상관의 정도를 나타내는 $\rho$ 또는 $r$로 표시되는 몇몇 상관계수가 있습니다. 이들 중 가장 널리 사용되는 것은 피어슨 상관계수(Pearson correlation coefficient)로 두 변수 사이의 선형관계를 잘 나타내 줍니다. 물론 한 변수가 다른 변수와 비선형관계일 때도 사용할 수 있습니다. 다른 상관계수는 Pearson 상관관계보다 강하게(robust) 개발되었기 떄문에 비선형 상관관계에서 더 민감합니다. 상호정보(Mutual information)는 두 변수 사이의 상관을 측정하는 데에도 적용될 수 있습니다.
출처
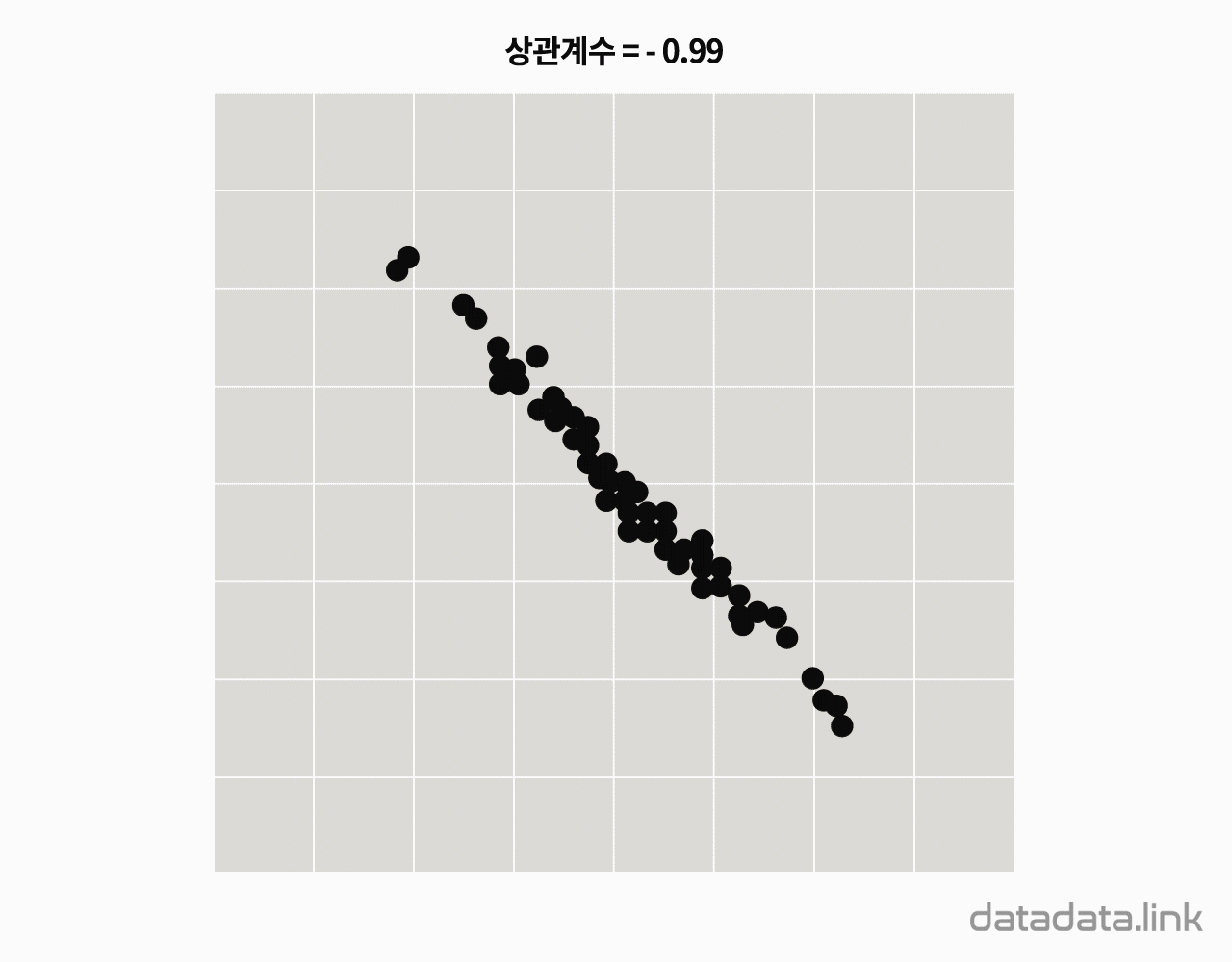
상관계수는 두 변수 간의 관계를 나타내는 수치입니다. 여기서 두 변수는 표본 데이터세트의 2개 열의 확률변수, 아니면 분포를 알고 있는 2개의 확률변수입니다.
상관계수는 -1에서 1 사이의 값들을 가지는데, 여기서 ±1은 가장 강한 상관이 있음을 나타내고 0은 상관관계가 없음을 의미합니다. 분석의 수단으로서, 상관계수는 특이성에 의해 왜곡되는 유형의 경향 및 두 변수간 인과 관계를 잘못 추론할 가능성이 있습니다.
출처
변동계수(Coefficient of variation), 상관계수(Coefficient of correlation)와 혼동하기 쉽습니다. 통계에서, 결정계수(coefficient of determination: R2 ,r2로 표현되며 R squared로 읽음) 는 독립변수들로부터 예측이 가능한 종속변수가 가지는 분산의 확률(예측이 가능하지 않은 종속변수와 상대비율)입니다.
통계적 모형(statistical models)에서 주로 사용되는 통계로써, 관련 정보를 통한 가설의 증명이나 미래의 일을 예상하는 데에 주로 사용됩니다. 결정계수는 통계적 모델로 표현된 결과의 전체 변동 비율에 따라 모델이 관찰된 결과를 얼마나 잘 반영했는지에 대한 수치를 제공합니다.
결정계수, $R^2$는 여러 정의가 존재합니다. 한 종류로는 $R^2$ 대신에 쓰여지는 $r^2$로 단순선형회귀(simple linear regression)가 있습니다. 절편(intercept)이 포함된 경우에는 관측된 결과와 예측값 사이의 표본상관계수($r$, correlation coefficient)의 제곱입니다. 회귀분석기(regressors)가 포함된 경우, R2는 다중상관계수(coefficient of multiple correlation)의 제곱입니다. 두 경우 모두, 결정계수는 0에서 1 사이입니다.
정의에 따라 $r^2$이 음수가 될 수 있습니다. 이는 해당 결과에 대한 예측이 모형(model)의 적합한 방식으로 도출되지 않았을 때에 발생할 수 있습니다. 또는 모형의 적합한 방식이 사용되더라도 여전히 음수일 수도 있습니다. 예를 들어, 절편을 포함하지 않고 선형회귀를 수행하거나, 데이터를 위해 비선형 함수를 사용할 경우에 음수가 될 수 있습니다. 음수가 되었다는 것은 특정 기준에 따라 데이터의 평균이 적합 함수값보다 더 적합하다는 뜻입니다. 결정계수의 가장 일반적인 정의는 “내쉬-서트클리프 모형 효율 계수(Nash–Sutcliffe model efficiency coefficient) “로도 알려져 있고, 이 표기법은 제곱기호가 있어서 혼동이 되기는 하지만 음의 값을 가지는 -∞에서 1까지의 범위를 가지는 적합도 지표를 나타내고 많은 분야에서 선호됩니다.
시뮬레이션값($Y_{pred}$)과 측정값($Y_{obs}$)의 적합도(the goodness-of-fit)를 평가할 때 선형회귀의 선형계수($R^2$)를 기반으로 하는 것은 적절하지 않습니다(i.e., $Y_{obs}= mY_{pred} + b$). 선형계수는 시뮬레이션값과 측정값의 선형 상관정도를 정량화하는 반면에, 적합도 평가의 경우에는 하나의 특정 선형 상관관계($Y_{obs}= Y_{pred} + b$ : the 1:1 line)만 고려해야 합니다.
출처 Coefficient of determination – Wikipedia