


범주형 변수는 변수값(관측값)이 범주(category)를 나타내는 값. 개체가 속하는 카테고리는 범주형 변수의 변수값으로 표현, 예를 들어, 인간이라는 범주형 변수에 남자와 여자라는 변수값이 있음.
범주형 변수 $X$는 $k$ 개의 범주를 가진다면, 이를 $C_1, C_2, \cdots, C_k$로 표현할 수 있음. 이때, 범주형 변수 $X$ 의 값은 다음과 같이 정의됨.
$$X \in \{ C_1, C_2, \ldots, C_k \}$$
개체의 속성을 나타내는 범주형 데이터는 명목형(Nominal) 또는 순서형(Ordinal) 으로 분류되며, 각 범주는 수치 값으로 인코딩될 수 있음.
범주형 확률변수는 특정 범주 $C_1, C_2, \cdots, C_k$에 속할 확률을 가지는 변수. 각 범주는 확률 $P(X=C_i)$로 표현됨.
$$X \in \{ C_1, C_2, \ldots, C_k \}, \quad P(X = C_i) \geq 0$$
모든 범주의 확률의 합은 1임. 즉, 확률변수 $X$는 다음과 같이 정의됨.
$$\sum_{i=1}^{k} P(X = C_i) = 1$$
범주형 변수 $X$는 $k$개의 범주 $C_1, C_2, \ldots, C_k$로 구성된 데이터임. 이를 Tensor로 표현하면, 범주형 변수 $X$는 차원이 $d$인 벡터 $\mathbf{X}$로 정의됨.
$$\mathbf{X} \in \mathbb{R}^{d}, \quad \mathbf{X} = [x_1, x_2, \ldots, x_d]^{\top}$$
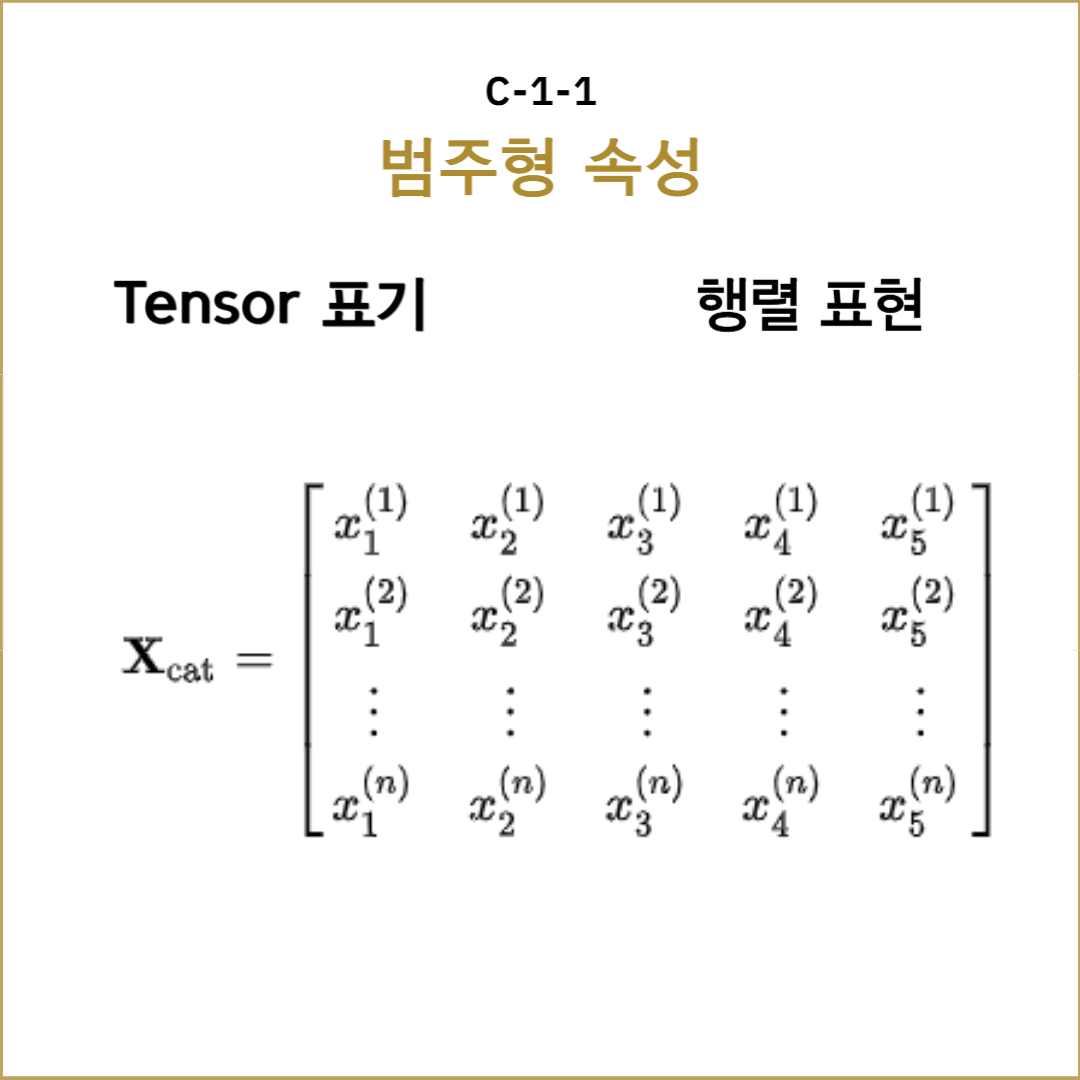
범주형 변수 $X$는 $n$개의 표본과 $k$개의 범주 $C_1, C_2, \ldots, C_k$로 구성된 데이터임. 이를 행렬로 표현하면, $X$를 $n\times k$ 크기의 행렬로 정의함. 각 행은 표본을 나타내며, 열은 각 범주를 의미.
$$\mathbf{X} \in \mathbb{R}^{n \times k}, \quad \mathbf{X} = \begin{bmatrix}
x_{11} & x_{12} & \ldots & x_{1k} \\
x_{21} & x_{22} & \ldots & x_{2k} \\
\vdots & \vdots & \ddots & \vdots \\
x_{n1} & x_{n2} & \ldots & x_{nk}
\end{bmatrix}
$$
연속형 변수 $X$는 실수 집합 $\mathbb{R}$에서 정의되는 변수로, 임의의 두 값 사이에 무한히 많은 값을 가짐. 예를 들어, 길이, 무게, 온도 등
$$X \in \mathbb{R}$$
연속형 확률변수 $X$는 확률분포에 따라 값이 할당되며, 확률밀도함수 $f(x)$를 사용하여 정의됨. 연속형 확률변수의 값이 특정구간 $[a, b]$에 속할 확률은 다음과 같음.
$$P(a \leq X \leq b) = \int_{a}^{b} f(x) \, dx$$
연속형 확률변수는 정규분포, 균등분포 등 다향한 분포로 표현될 수 있음.
연속형 변수 $X$는 실수집합 $\mathbb R$에서 정의되며, 여러 개의 표본과 특성을 포함하는 경우 Tensor로 표현됨. 텐서 표현은 일반적으로 다차원 배열로 나타내며, 차원수를 랭크(rank)라고 함.
$$\mathbf{X} \in \mathbb{R}^{n_1 \times n_2 \times \ldots \times n_k}$$
텐서 $\mathbf X$는 $k$-차원으로 표현되며, 각 차원은 표본의 수, 특성 수 등을 포함. 예들 들어, 연속형 변수를 $n$개의 표본과 $d$개의 특성을 가진 2차원 텐서로 표현하면 다음과 같음
$$\mathbf{X} \in \mathbb{R}^{n\times d}$$
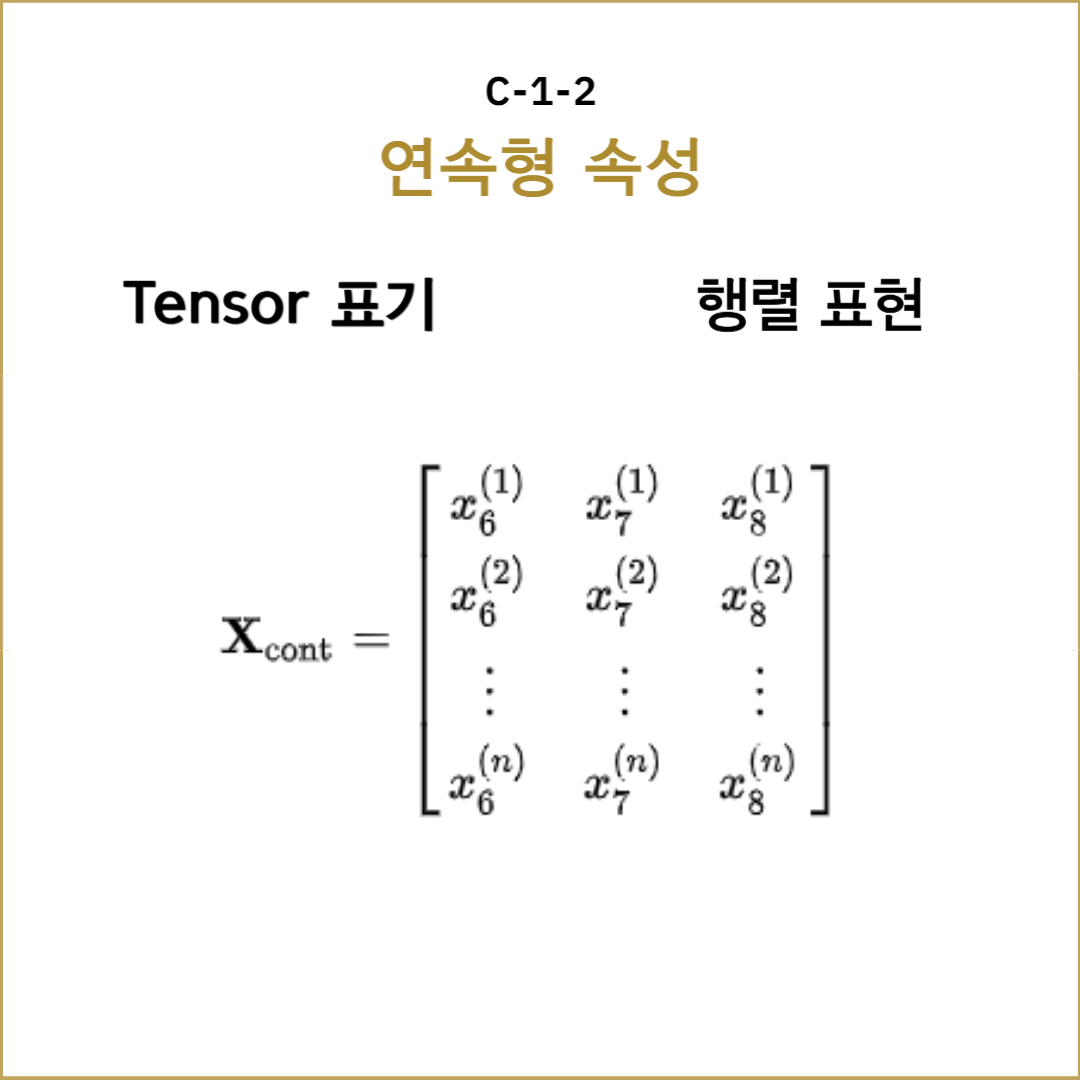
연속형 변수 $X$는 실수값을 가지며, $n$개의 표본과 $d$개의 특성(feature)으로 구성된 데이터임. 이를 행렬로 표현하면, $X$를 $n\prod d$ 크기의 행렬로 정의함. 각 행은 표본을 나타내며, 열은 각 특성을 의미.
$$\mathbf{X} \in \mathbb{R}^{n \times d}, \quad \mathbf{X} = \begin{bmatrix}
x_{11} & x_{12} & \ldots & x_{1d} \\
x_{21} & x_{22} & \ldots & x_{2d} \\
\vdots & \vdots & \ddots & \vdots \\
x_{n1} & x_{n2} & \ldots & x_{nd}
\end{bmatrix}$$
연속형 변수는 실수값 범위에서 정의되며, 행렬 $X$의 원소 $x_{ij}$는 다음으로 표현됨.
$$x_{ij} \in \mathbb{R}$$
| 속성 간 관계 | 설명 | 특징 |
|---|---|---|
선형회귀 (Linear Regression) | 두 변수 사이의 선형 관계를 추정하는 방법으로, 직선 형태로 모델링함. | 연속형 변수 예측에 유용, 단순하고 해석 가능. |
로지스틱회귀 (Logistic Regression) | 범주형 결과 변수를 예측하기 위해 사용되며, 시그모이드 함수로 확률을 계산함. | 이진 분류에 주로 사용되며, 확률 값을 출력함. |
상관관계 (Correlation) | 두 변수 간의 선형적 관계의 강도를 나타내며, 값은 -1에서 1 사이를 가짐. | 상관계수로 관계의 방향성과 강도를 나타냄. |
공분산 (Covariance) | 두 변수 간의 변동 정도를 측정하며, 양수는 같은 방향, 음수는 반대 방향의 변화를 의미함. | 단위에 따라 값이 달라지며, 해석이 어려울 수 있음. |
의사결정나무 (Tree Model) | 데이터의 특징을 기준으로 분기하여 예측 또는 분류를 수행하는 비선형 모델. | 비선형 관계를 효과적으로 모델링할 수 있음. 해석이 용이함. |
신경망 모델 (Neural Networks) | 다층 구조를 사용하여 입력 데이터를 처리하고 학습하여 예측 또는 분류를 수행하는 모델. | 복잡한 관계를 학습 가능. 비정형 데이터에도 적용 가능. |
상호작용 항 (Interaction Term) | 두 변수의 결합 효과를 고려하는 변수로, 독립 변수 간의 상호 영향을 모델링함. | 비선형 상호작용을 반영할 수 있어 예측 성능을 향상시킬 수 있음. |
다변량 정규분포 (Multivariate Normal) | 여러 변수의 분포를 동시에 고려하는 확률 분포로, 공분산 행렬로 관계를 나타냄. | 변수 간의 상관성을 반영하며, 통계적 분석에 널리 사용됨. |
| 데이터 생성 방법 | 장점 | 단점 |
|---|---|---|
| 통계적 분포 기반 생성 | 간단하고 이론적으로 잘 정의된 데이터 생성 가능. | 실제 데이터의 복잡한 특성을 반영하기 어려움. |
| 회귀 모델 기반 데이터 생성 | 예측 변수와 결과 변수의 관계를 쉽게 모방 가능. | 모델 구조에 의존하며, 복잡한 패턴은 잘 표현하지 못함. |
| 다변량 분포 기반 생성 | 다수의 변수 간 상관성을 유지하며 데이터 생성 가능. | 정확한 공분산 행렬을 추정하는 데 어려움이 있을 수 있음. |
| 부트스트랩 방법 | 샘플링을 반복하여 데이터의 통계적 특성을 보존 가능. | 데이터의 변동성을 충분히 반영하지 못할 수 있음. |
| 몬테카를로 시뮬레이션 | 임의성을 활용하여 다양한 시나리오를 평가 가능. | 많은 연산이 필요하며 계산 비용이 큼. |
| Synthetic Data Generation | 복잡한 데이터 구조를 모델링하여 현실적인 데이터 생성 가능. | 모델 학습 및 검증에 시간과 리소스가 많이 필요함. |